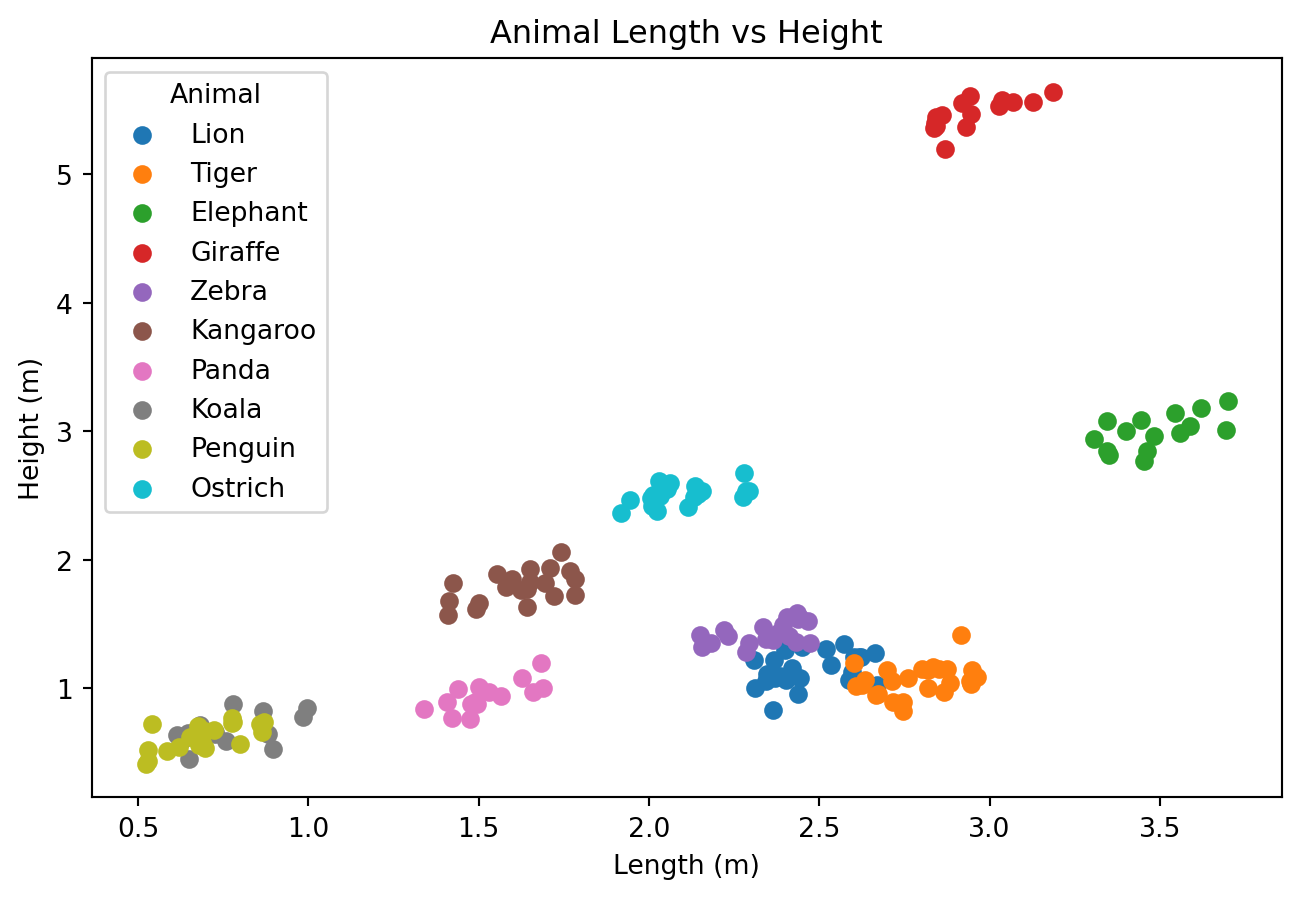
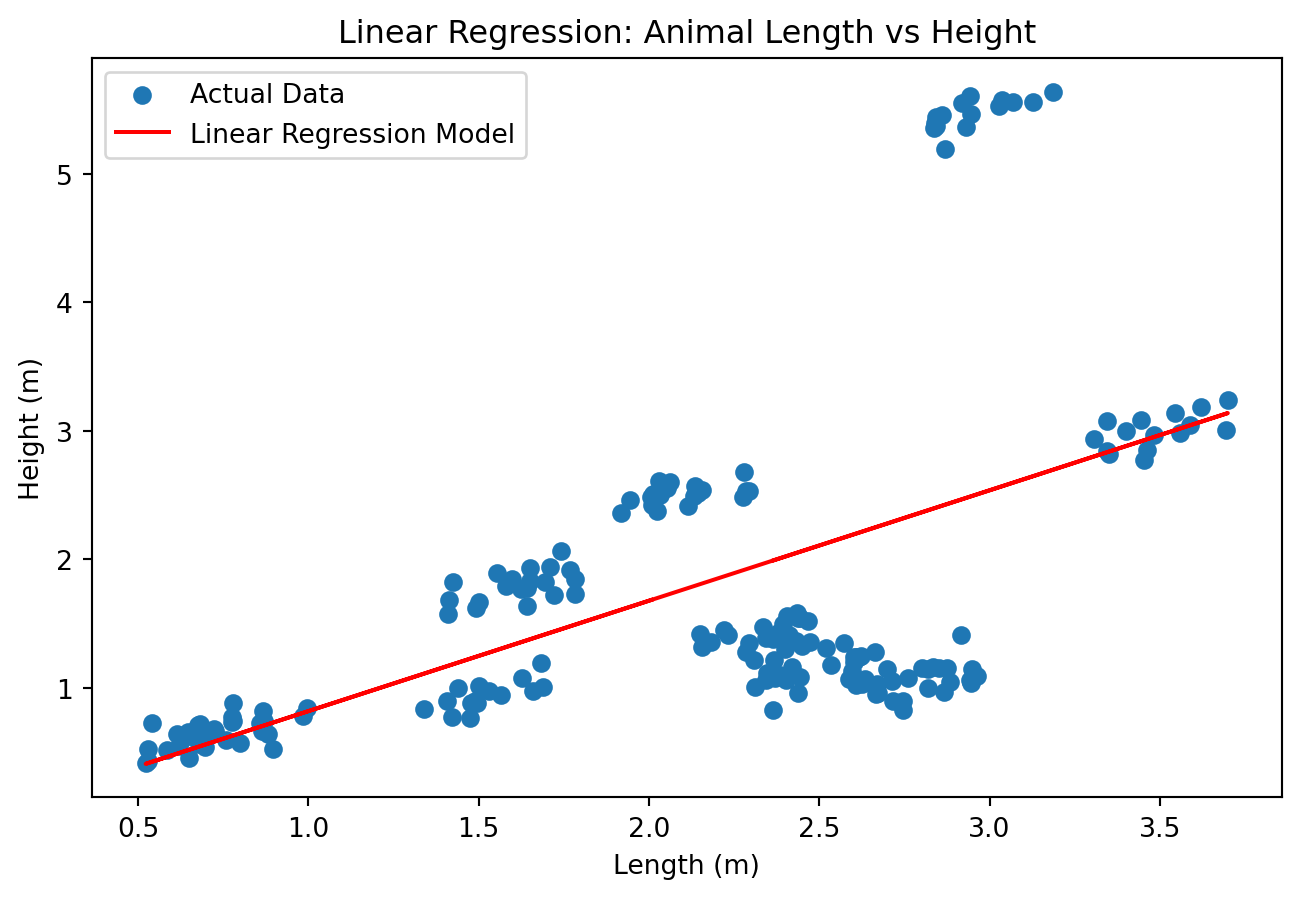
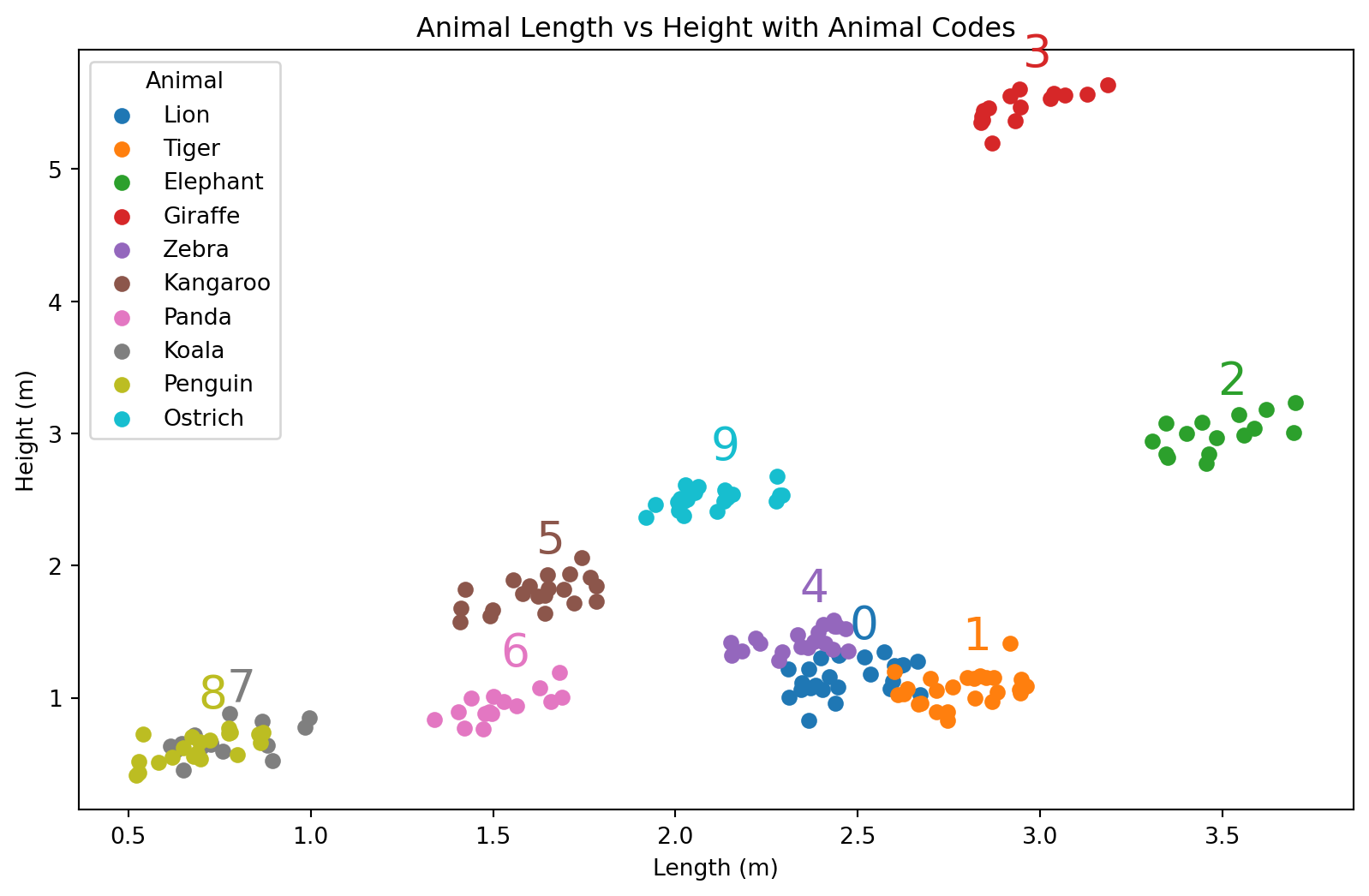
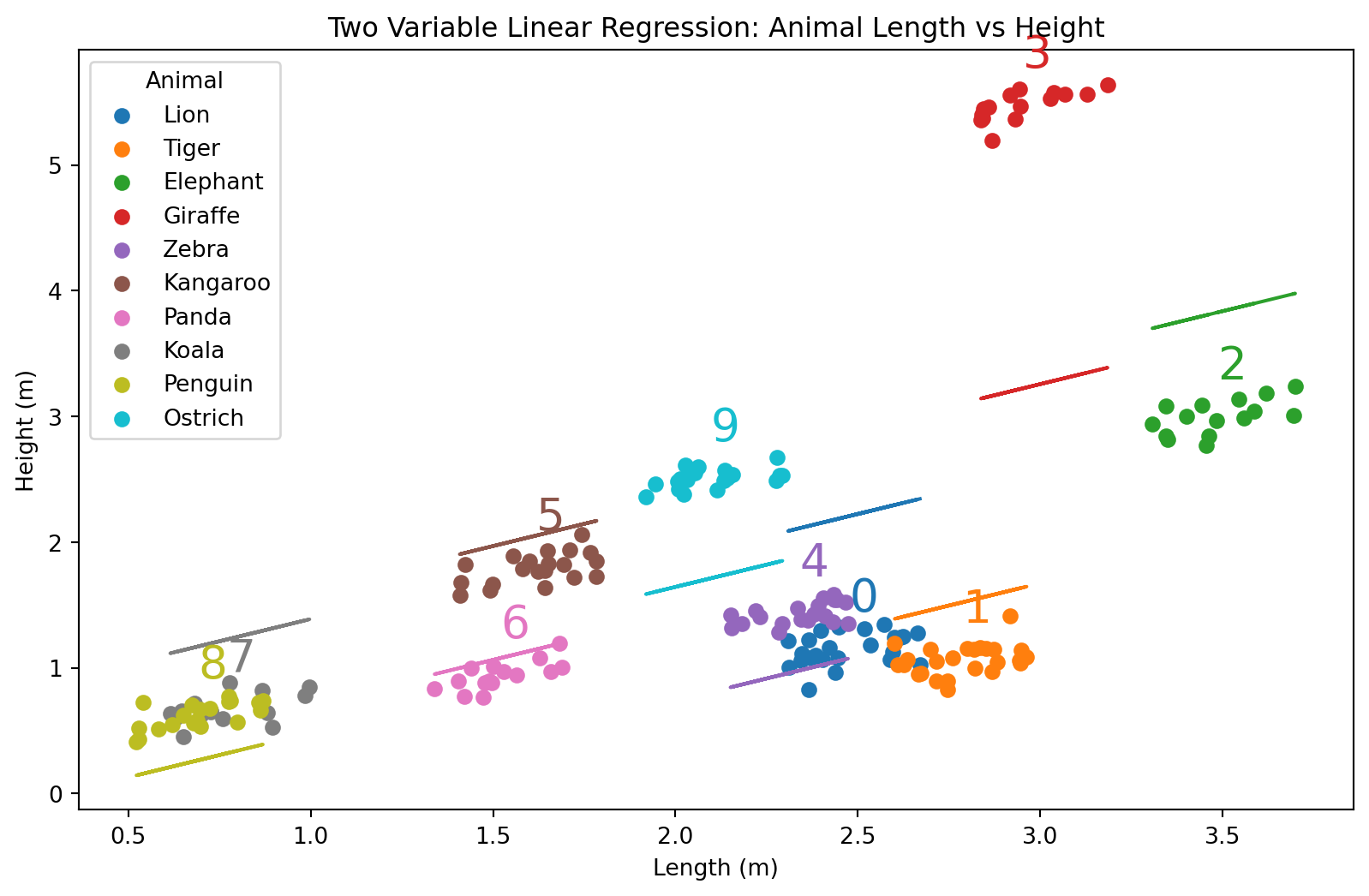
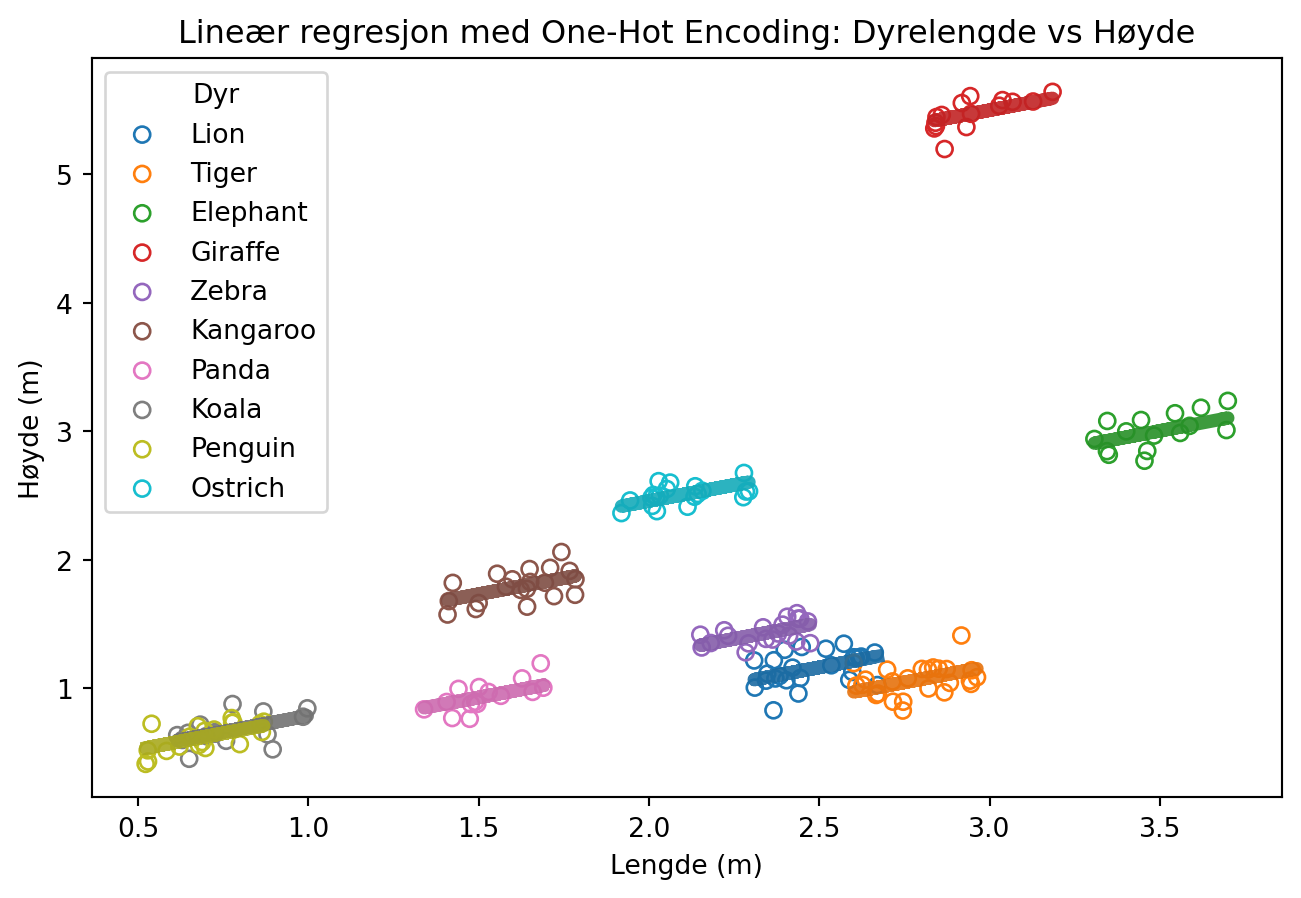
Vi kan lage one-hot-kodet data med pandas.get_dummies(...)
Length
Height
Animal_Code
Animal_Elephant
Animal_Giraffe
Animal_Kangaroo
Animal_Koala
Animal_Lion
Animal_Ostrich
Animal_Panda
Animal_Penguin
Animal_Tiger
Animal_Zebra
122
1.643661
0.986154
6
False
False
False
False
False
False
True
False
False
False
97
2.465034
1.408103
9
False
False
False
False
False
False
False
False
False
True
144
0.785886
0.591844
3
False
False
False
True
False
False
False
False
False
False
32
2.669382
1.146243
8
False
False
False
False
False
False
False
False
True
False
86
2.464493
1.340952
9
False
False
False
False
False
False
False
False
False
True
66
2.996168
5.573149
1
False
True
False
False
False
False
False
False
False
False
92
2.144048
1.372957
9
False
False
False
False
False
False
False
False
False
True
38
2.709070
1.083163
8
False
False
False
False
False
False
False
False
True
False
132
1.481725
0.821179
6
False
False
False
False
False
False
True
False
False
False
84
2.199283
1.296119
9
False
False
False
False
False
False
False
False
False
True
Regresjonsmodell med one-hot-coding
Likning
\[H(L, N) = \beta_0 + \beta_1 L + \sum_{\mathrm{i = \{Lion, Tiger, ...\}}}^{k} \beta_i [\text{er dette en }i\mathrm{?}]\]
La oss se på dette i et litt mindre datasett
import pandas as pdimport seaborn as snshealth = sns.load_dataset('healthexp')display(health.sample(10))
Year
Country
Spending_USD
Life_Expectancy
148
2000
Canada
2450.593
79.1
46
1981
Japan
603.965
76.5
226
2013
Canada
4428.753
81.7
89
1990
Canada
1699.774
77.3
168
2003
France
3056.265
79.3
183
2005
USA
6430.757
77.6
237
2014
USA
8925.879
78.9
152
2000
Japan
1847.786
81.2
255
2017
USA
10046.472
78.6
4
1970
USA
326.961
70.9
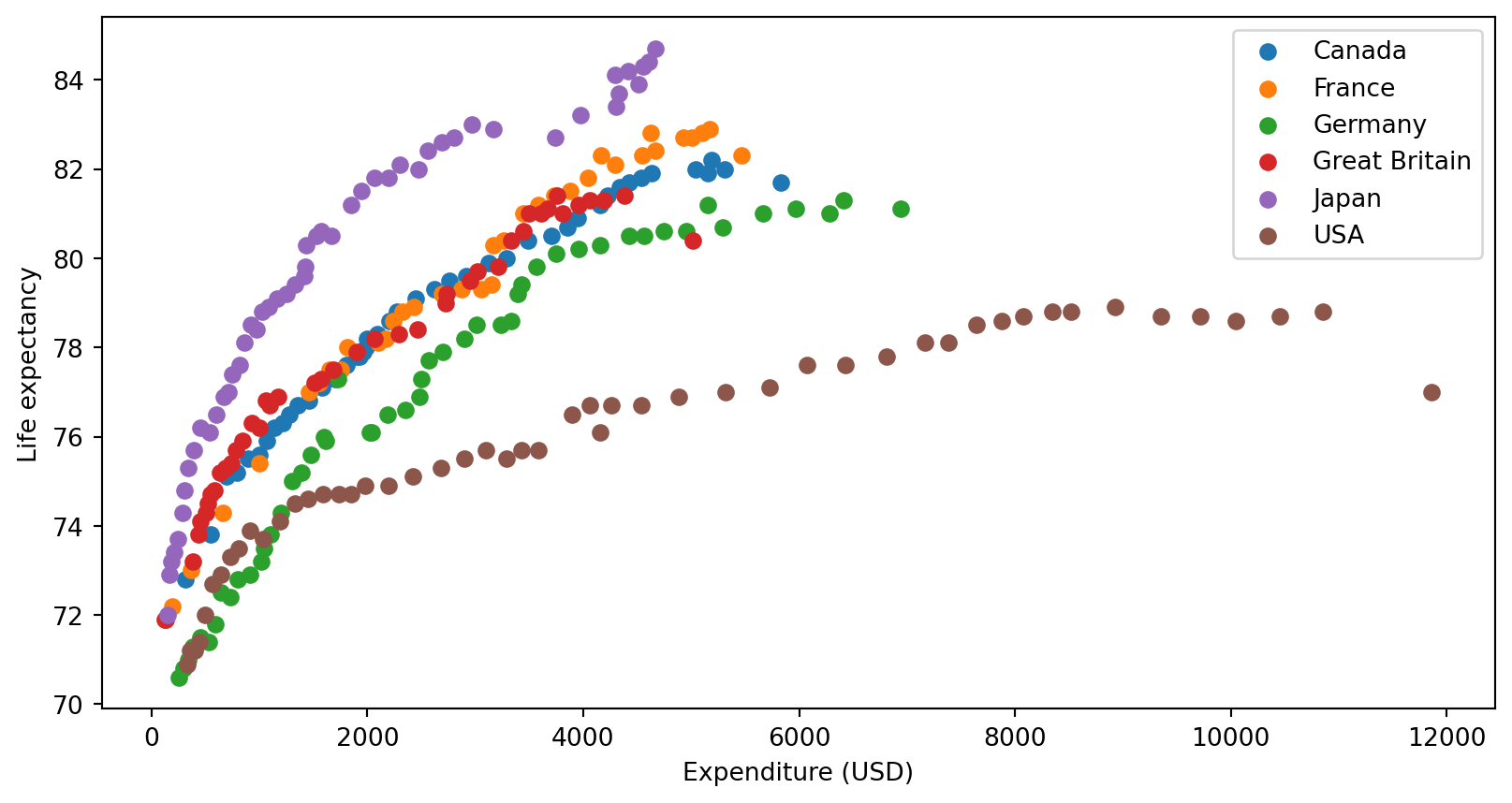
Her bruker vi seaborn kun for å laste inn et datasett. Seaborn gir oss også noen muligheter til pen visualisering i statistikk, for dem som måtte være interessert i det.
Underveisoppgave
Note
Gjør one-hot encoding av healthexp-datasettet
Gjør trenings-validerings-splitt av datasettet
Tren en lineær regresjonsmodell for å predikere life expectancy, med spending som forklaringsvariabel
Ta med land som forklaringsvariabel i modellen
Sammenligne nøyaktigehten til modellene
import pandas as pdimport seaborn as snshealth = sns.load_dataset('healthexp')health_onehot = pd.get_dummies(health, columns=['Country'])display(health_onehot.sample(10))
Year
Spending_USD
Life_Expectancy
Country_Canada
Country_France
Country_Germany
Country_Great Britain
Country_Japan
Country_USA
7
1971
134.172
71.9
False
False
False
True
False
False
262
2019
5189.721
82.2
True
False
False
False
False
False
102
1992
1651.139
77.5
False
True
False
False
False
False
128
1996
1436.372
80.3
False
False
False
False
True
False
43
1981
898.807
75.5
True
False
False
False
False
False
84
1989
1579.543
77.1
True
False
False
False
False
False
182
2005
2471.186
82.0
False
False
False
False
True
False
260
2018
4554.276
84.3
False
False
False
False
True
False
95
1991
1805.209
77.6
True
False
False
False
False
False
164
2002
2065.133
81.8
False
False
False
False
True
False
Start på løsning
Year
Country
Spending_USD
Life_Expectancy
119
1995
Germany
2349.145
76.6
184
2006
Canada
3486.621
80.4
50
1982
Great Britain
448.477
74.1
65
1985
France
1001.145
75.4
265
2019
Great Britain
4385.463
81.4
73
1986
USA
1847.773
74.7
35
1979
Japan
452.931
76.2
193
2007
Great Britain
3021.671
79.7
10
1972
Germany
337.364
71.0
206
2009
Japan
2971.377
83.0
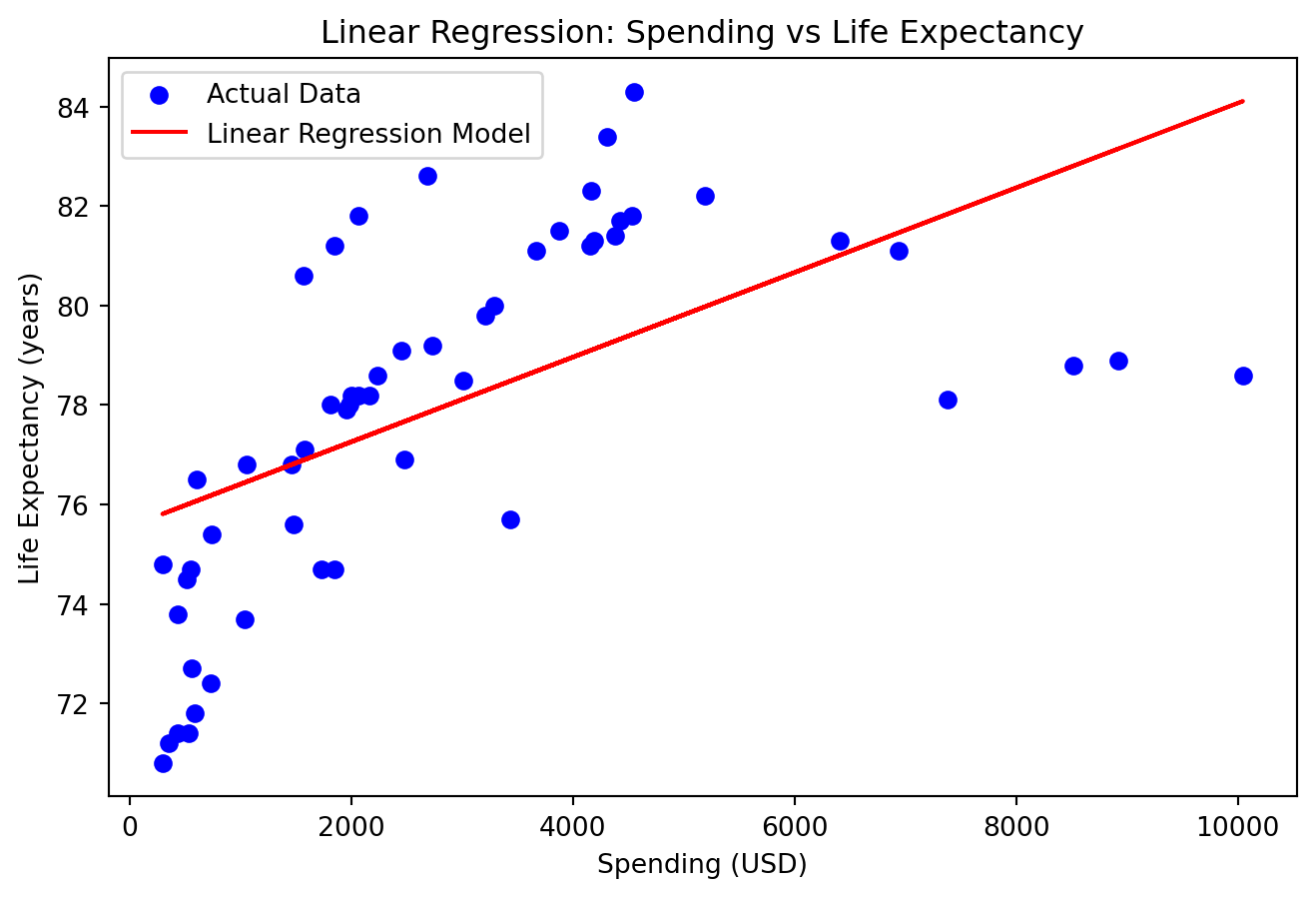
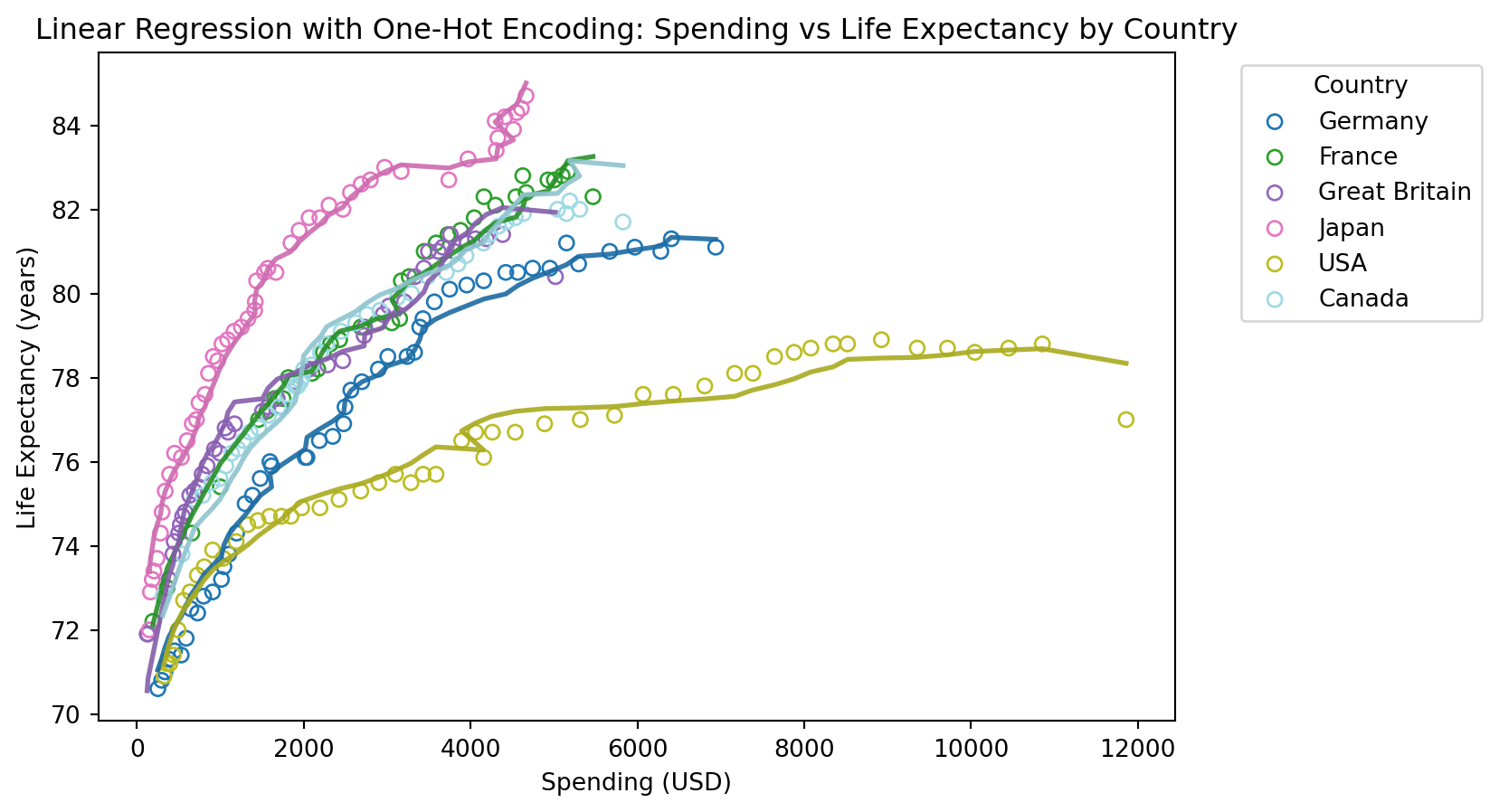
Enkel regresjonsmodell
Mean Squared Error: 7.846016617615249
R^2 Score: 0.3573359515082699
En påfallende “god” modell, hva har skjedd her?
Mean Squared Error: 0.13772868450148823
R^2 Score: 0.9887186991451887
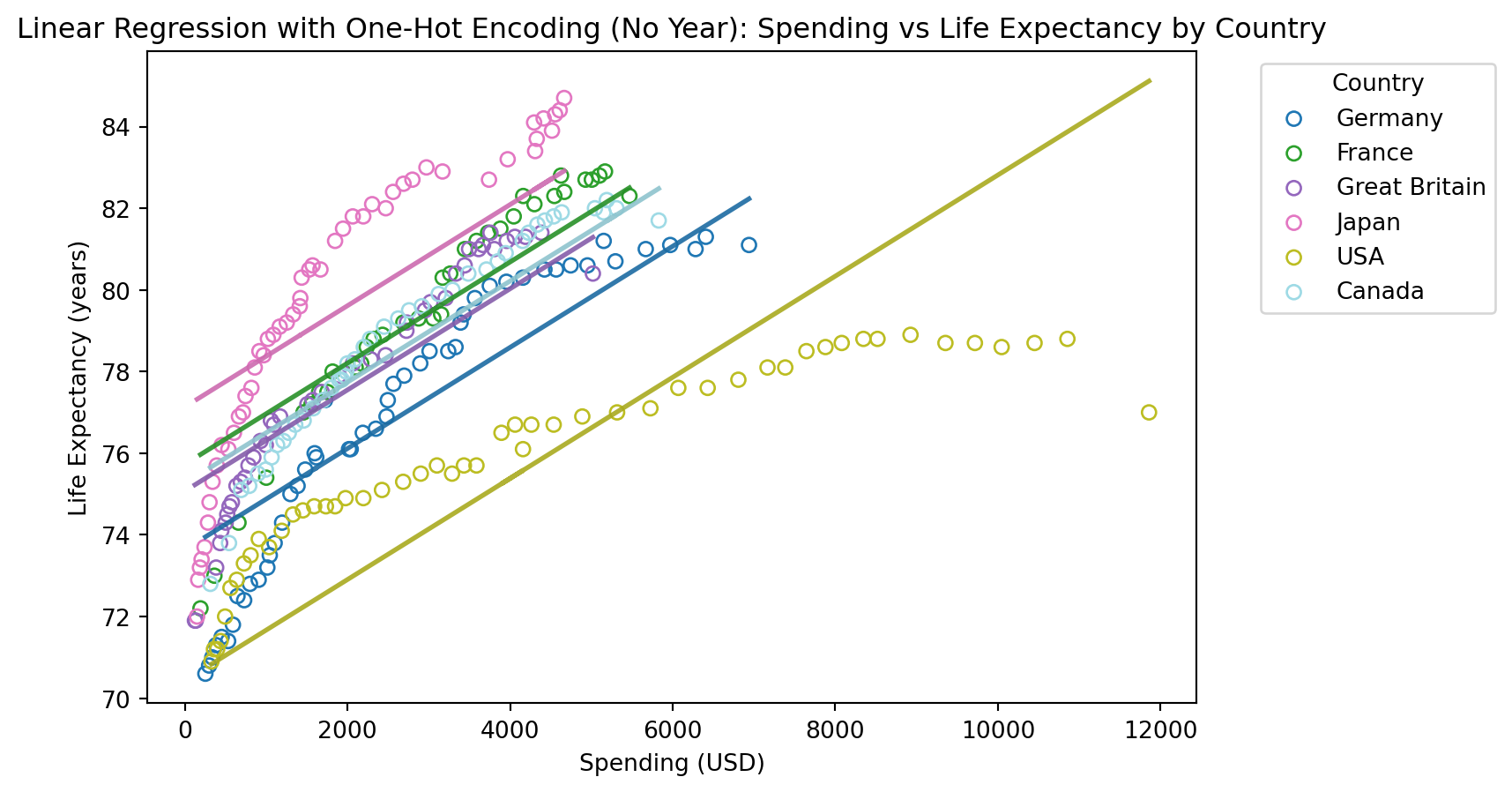
Uten år som forklaringsvariabel
Mean Squared Error: 2.301373209783868
R^2 Score: 0.8114954509821515