Kunne lese inn og utforske datasett i jupyter notebook m/numpy, pandas og matplotlib
Praktisk info
Undervisning på fredager 08:15–10:00
1 oblig (frist om en god stund)
2 prosjekter
Muntlig eksamen
Nettressurser lenket fra emnesiden. Disse endres gjennom semesteret
Undervisere
Henrik Sveinsson (Emneansvarlig)
Forsker i fysikk
Ane Kristine Espeseth (Seminarlærer)
Jobber med doktorgrad i kunstig intelligens
Aksel Sterri (Digital etikk)
PhD i filosofi
Forskningsdirektør i tenketanken Langsikt
Plan for semesteret
Statistikk og databehandling (januar-februar)
Forstå og anvende sentrale konsepter innen statistikk (Lineær og logistisk regresjon, Beslutningstrær)
forstå, bearbeide, analysere og visualisere datasett av moderat størrelse på en informert måte, samt trekke etterprøvbare konklusjoner
Digital etikk (mars)
vurdere etiske utfordringer med KI-algoritmer
se hvordan opprinnelsen til et datasett legger føringer og begrensninger på hva man kan bruke datasettet til
Prosjektoppgave (mars-mai)
Jobbe med prosjekt i tverrfaglige team og kommunisere resulatene muntlig og skriftlig
Husk
Hjelp hverandre (skal vi sette opp grupper?)
Følg med på semestersidene
Studentrepresentanter
Still gjerne spørsmål etter timen
Send mail om det er noe
More is different
SHOT
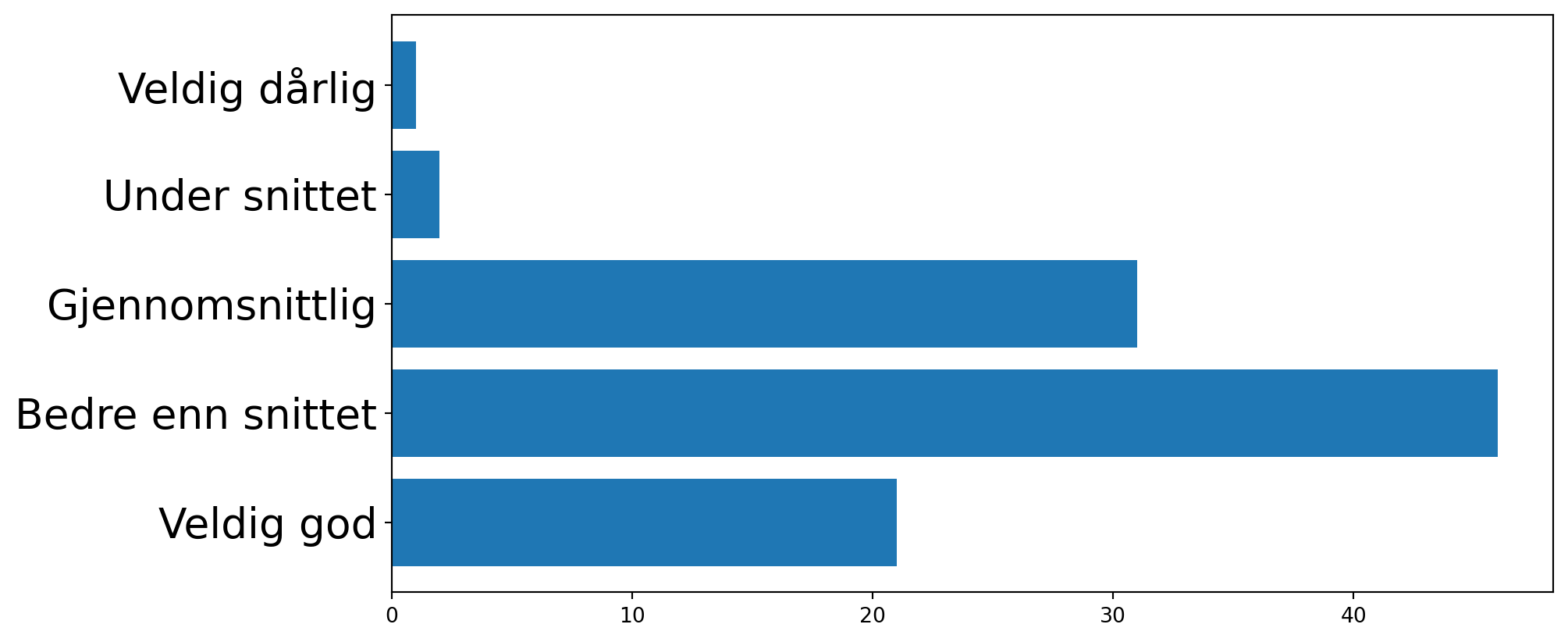
Omtrent 4 av 10 studenter (42 %) oppgir at de har god eller svært god livskvalitet. Samtidig vurderer 31 % av studentene sin livskvalitet som litt under middels eller dårligere
Bør vi sette inn tiltak?
Studenter flest mener de har det bedre enn snittet (!)
Sjåfører
import matplotlib.pyplot as plt import pandas as pdferdighetsnivå = ["Veldig god", "Bedre enn snittet", "Gjennomsnittlig", "Under snittet", "Veldig dårlig"]andel = [21, 46, 31, 2, 1]plt.barh(ferdighetsnivå, andel)plt.tick_params(axis='y', labelsize=20)
Hva så?
Henger dette på greip?
Kan dette i prinsippet henge på greip?
Kom med en hypotese basert på dette datasettet.
Hvilke data trenger du å samle inn for å vurdere hypotesen din?
Å kunne håndtere data med Pandas
Aritmetikk i jupyter notebook
(Prøv å kjøre dette i egen notebook, meld ifra med postitlapp om det ikke er mulig å holde følge)
a =3b =4c = a*bprint("a*b = %i"%(a*b))
a*b = 12
Legge til ny/fjerne celle
Kommer an på VSCode/jupyter notebook/juyter lab
Legg til en ny celle i din notebook
Bruke celle til tekst (inkl. latex)
Sette celletype til “Markdown”
Markdown-celle
Her kan jeg skrive tekst-innhold, likninger og slikt. $\int_0^\infty f(x) dx$
Markdown-celle
Her kan jeg skrive tekst-innhold, likninger og slikt. \(\int_0^\infty f(x) dx\)
Installere pakker i Jupyter
!pip install <pakkenavn>
!pip install matplotlib
Legge på -q (quiet) for å ikke spamme output-cellen
!pip install -q matplotlib
Med følgende får vi gjort mye:
!pip install -q matplotlib numpy pandas
Importere pakker
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd
Feilmeldinger?
Funker installasjon og import av disse pakkene? Opp med grønn/rød postit!