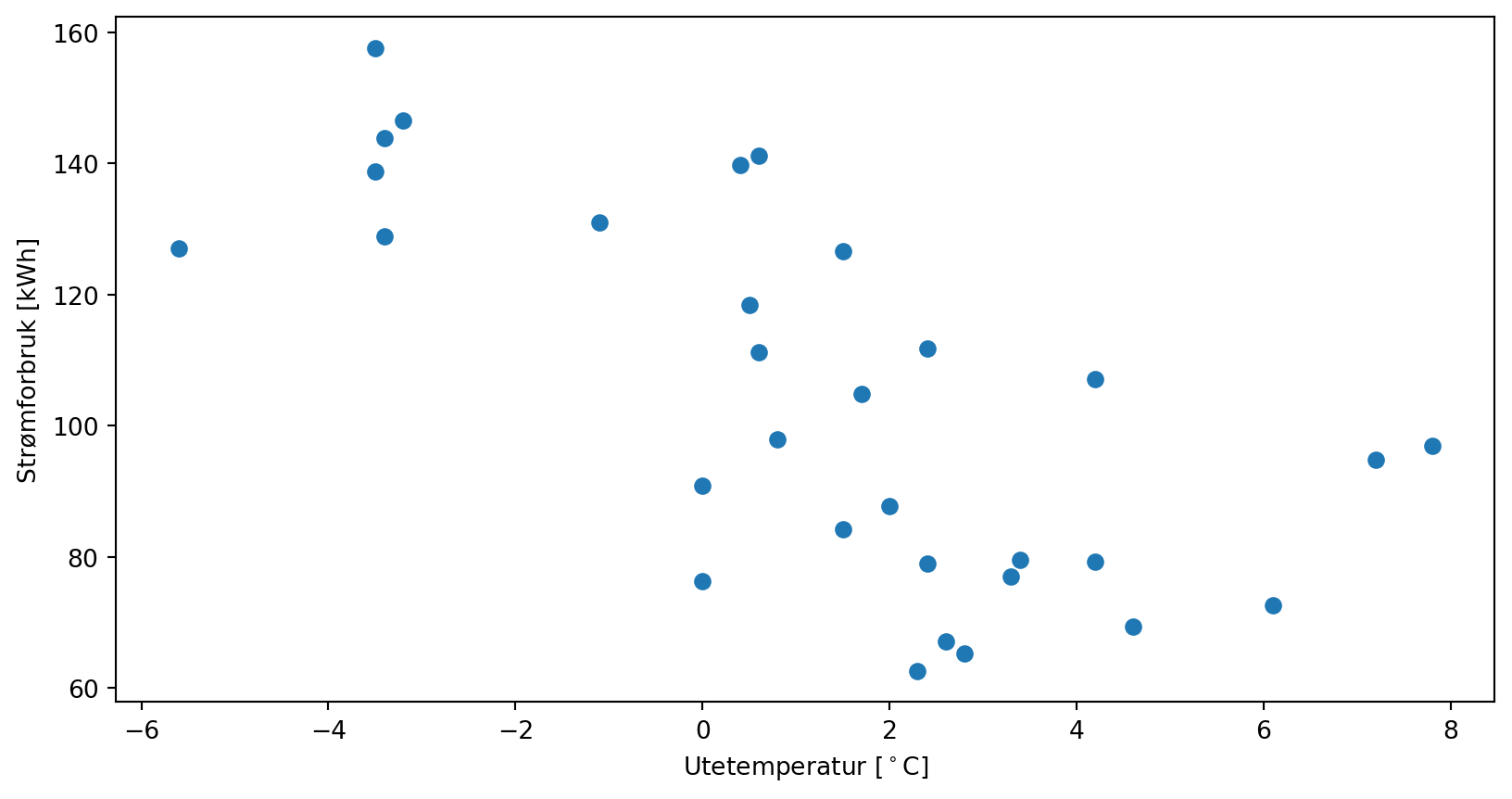
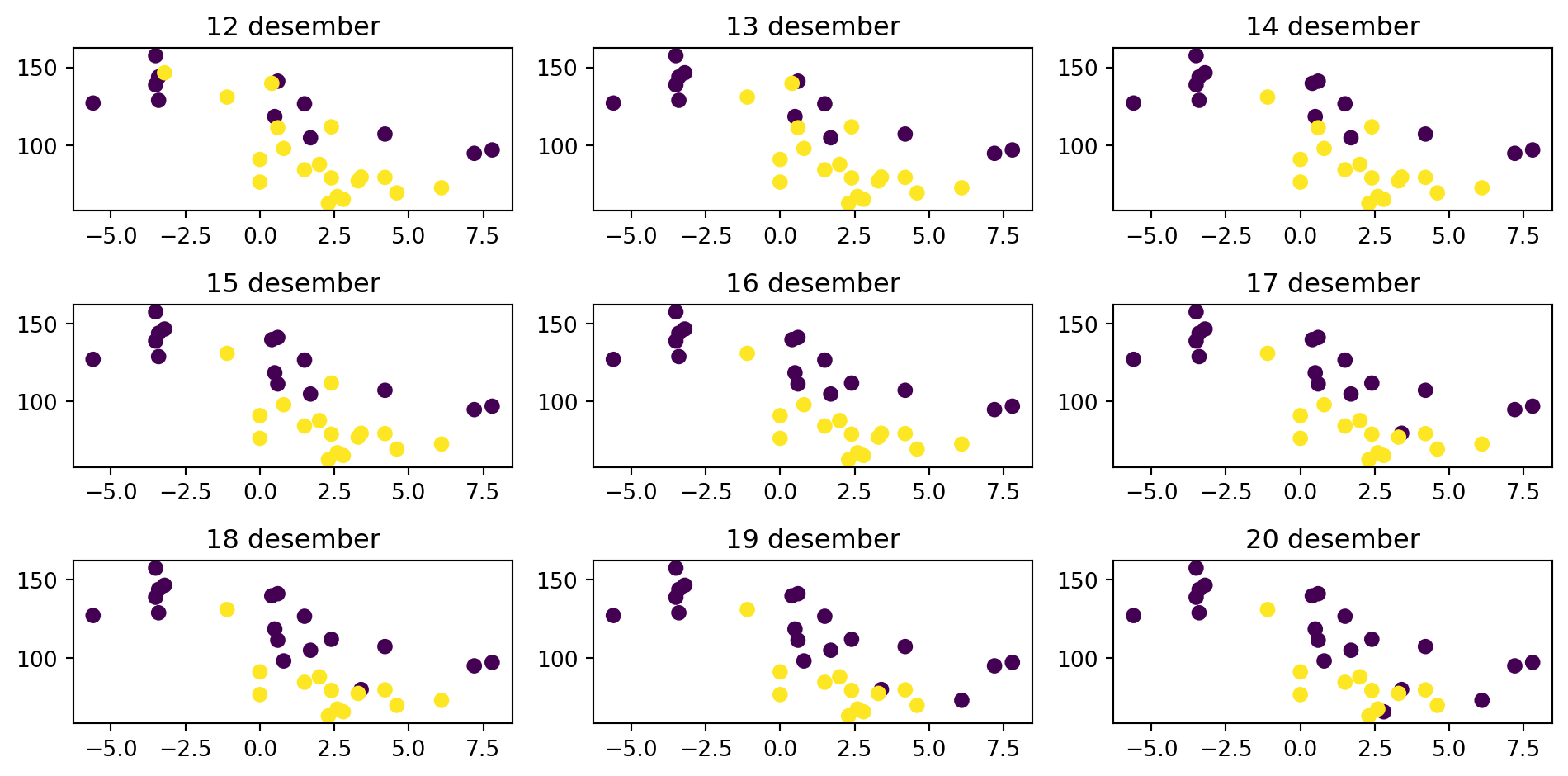
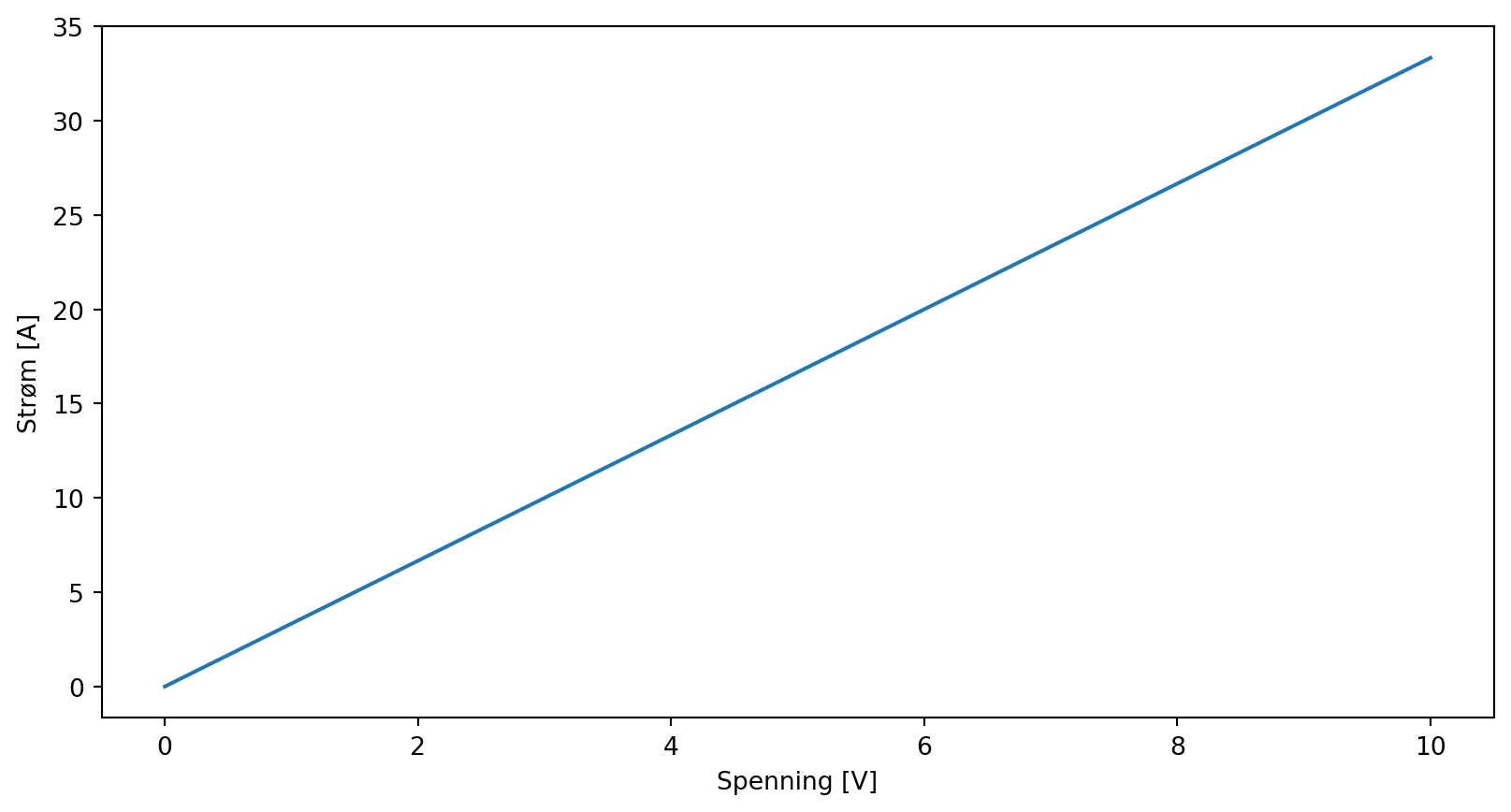
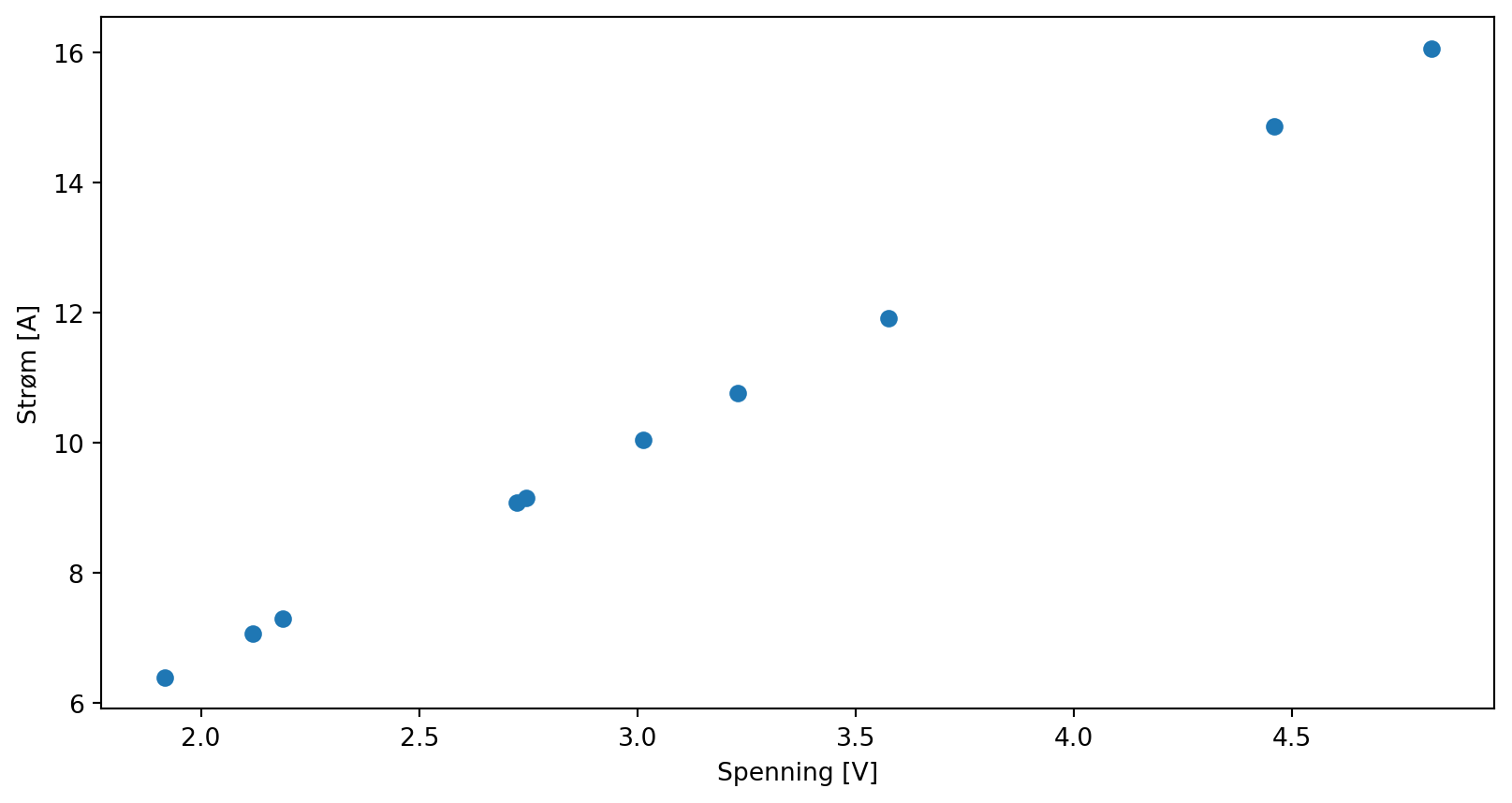
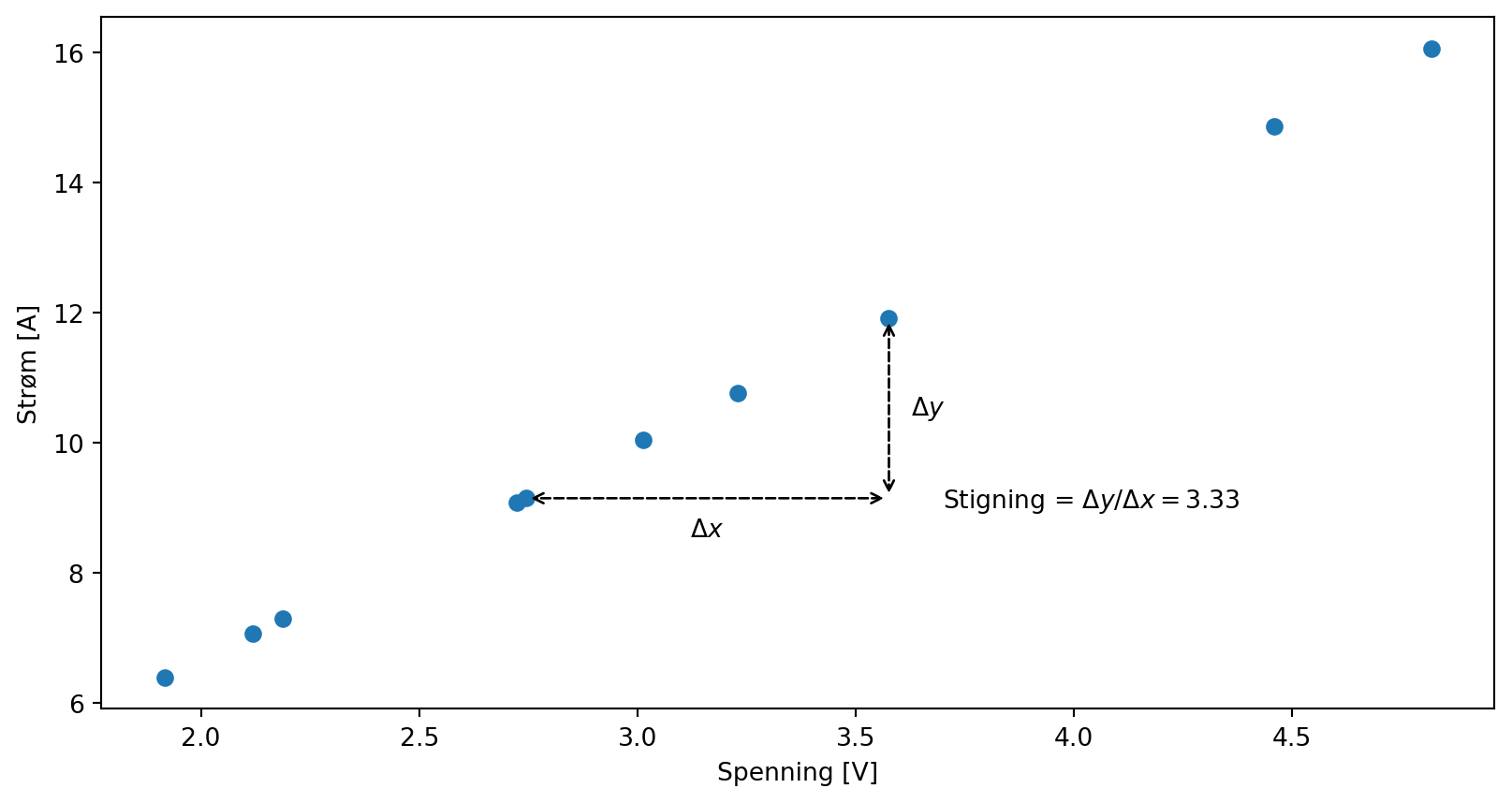
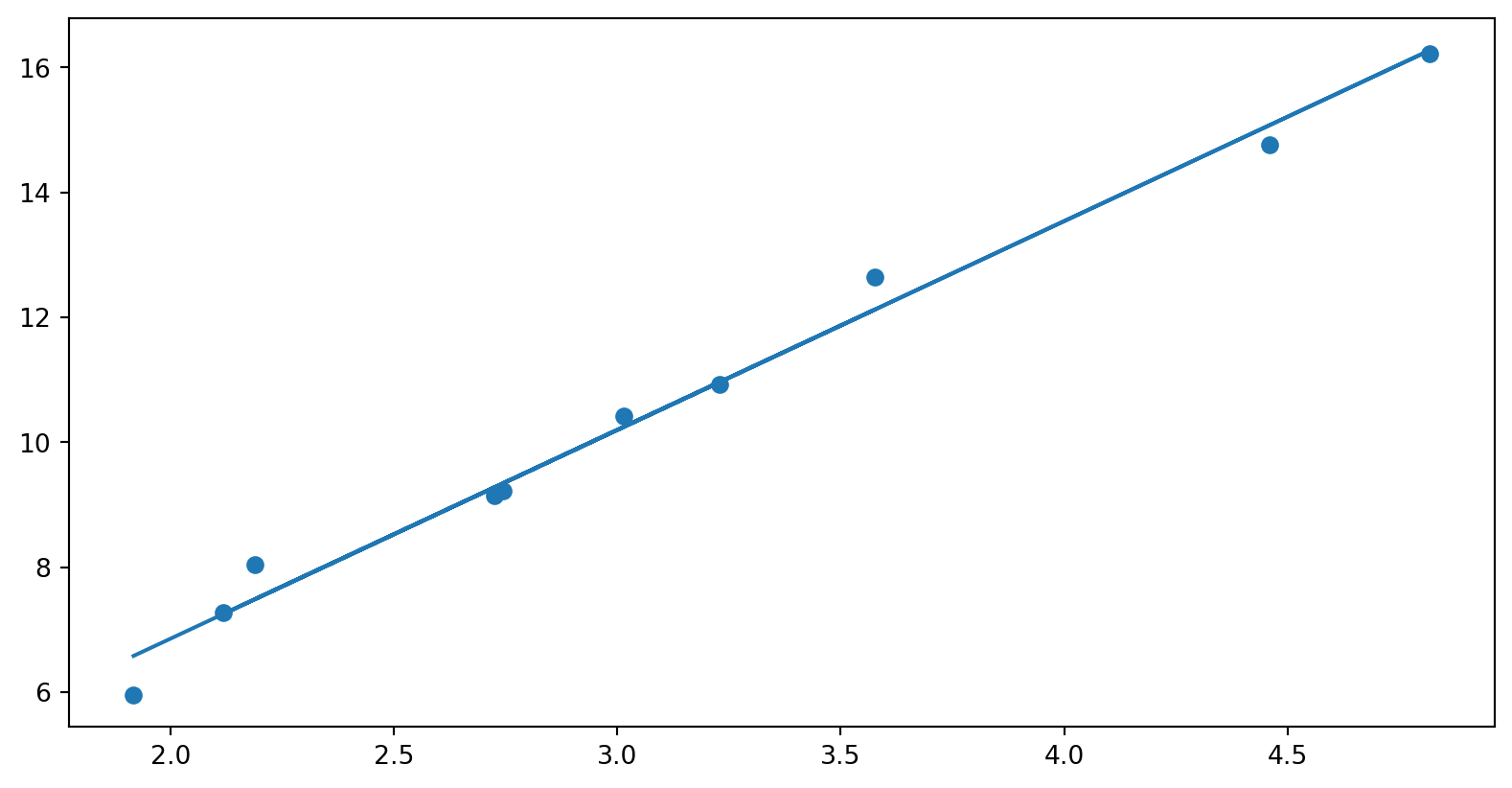
a) Lag deg en affin funsjon (f. eks \(f(x) = 2x + 3\)). Trekk 10 tilfeldige tall, beregn \(f(x) + \varepsilon\) der du setter inn et tilfeldig normalfordelt tall som \(\varepsilon\) med np.random.normal(...). Verifiser med et plott at ting fungerer som de skal
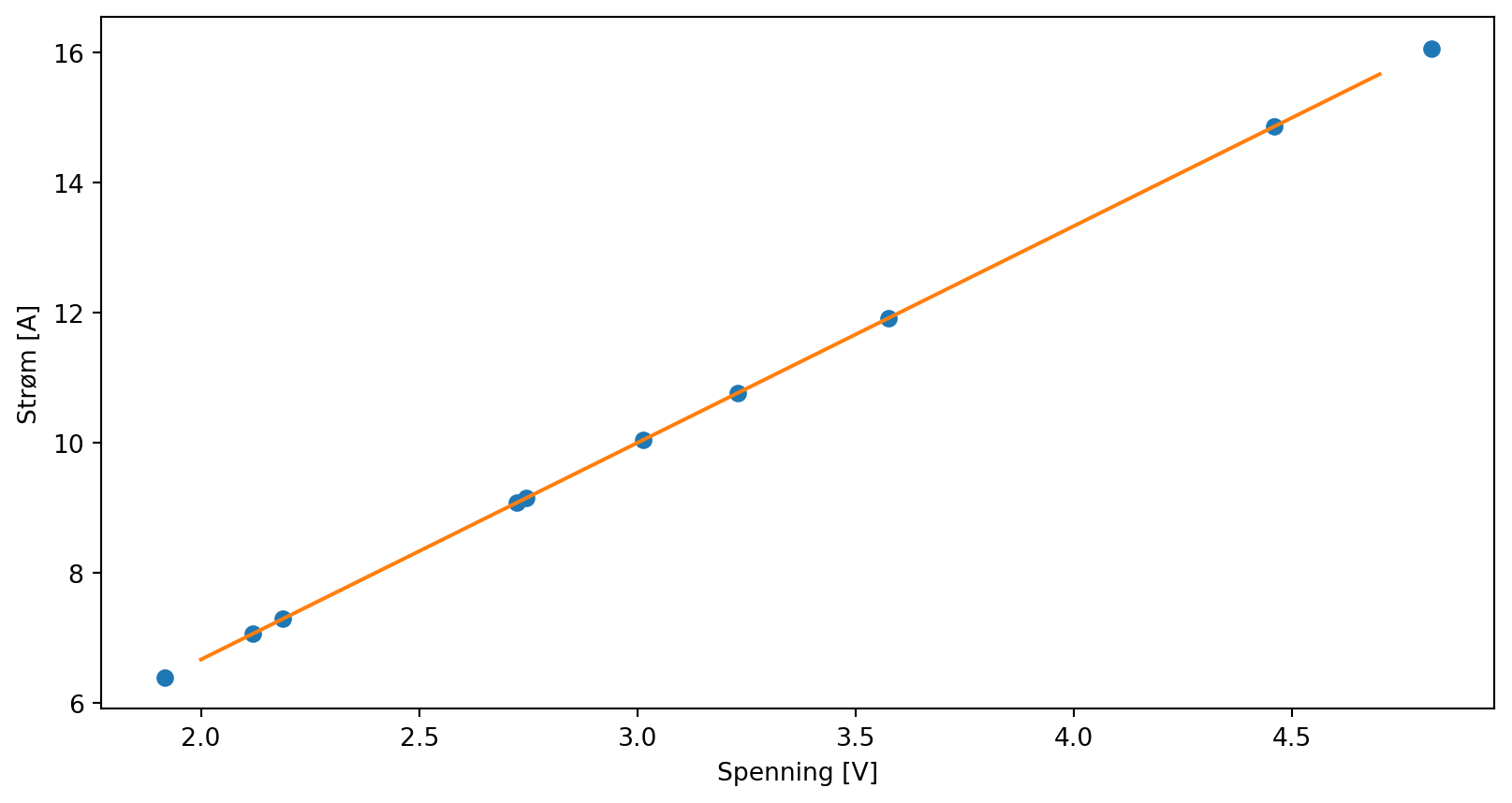
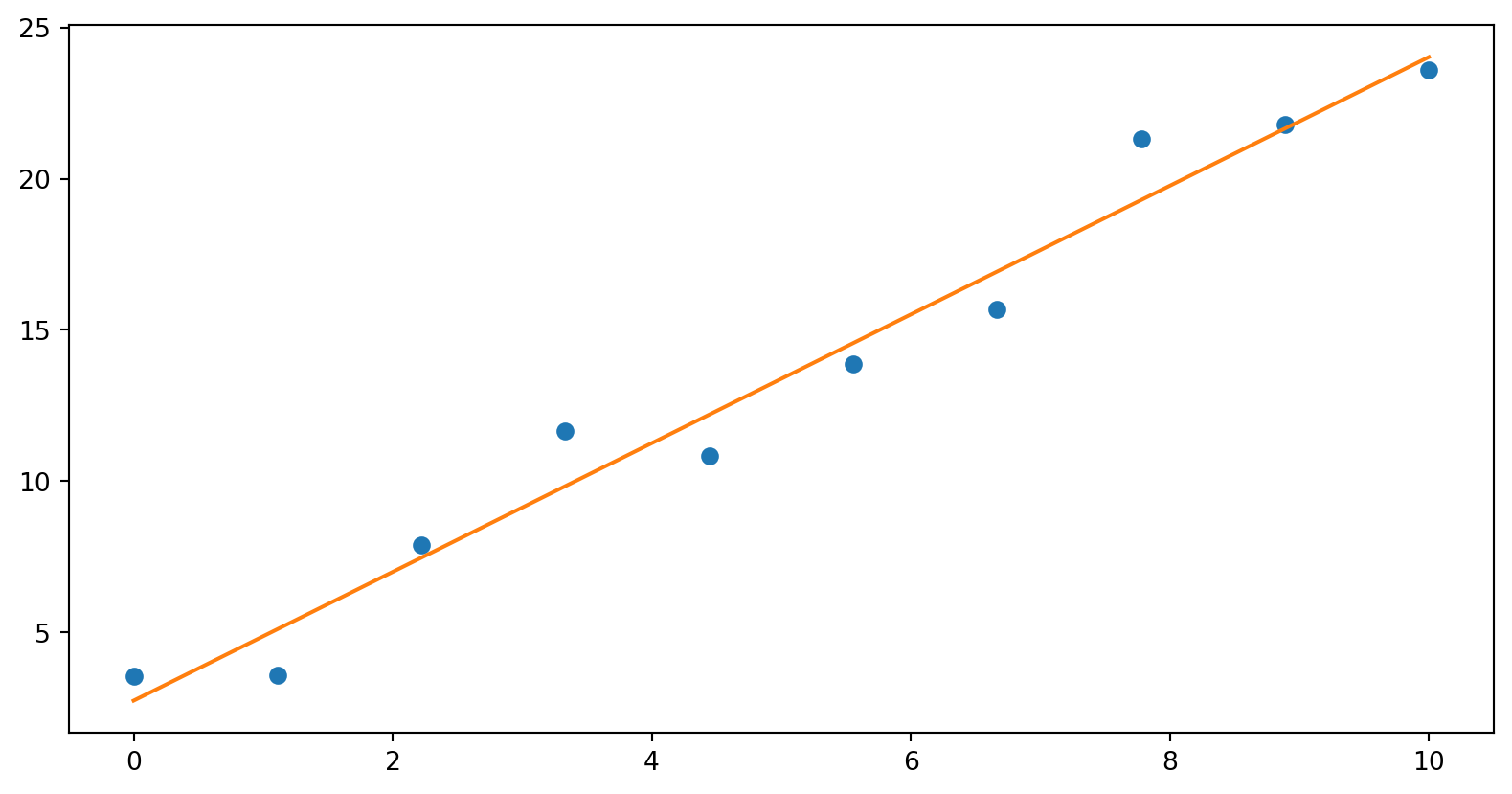
b) Gjør en lineærtilpasning med np.polyfit(x, y, 1). Plott lineærtilpasningen sammen med de litt spredte punktene dine.
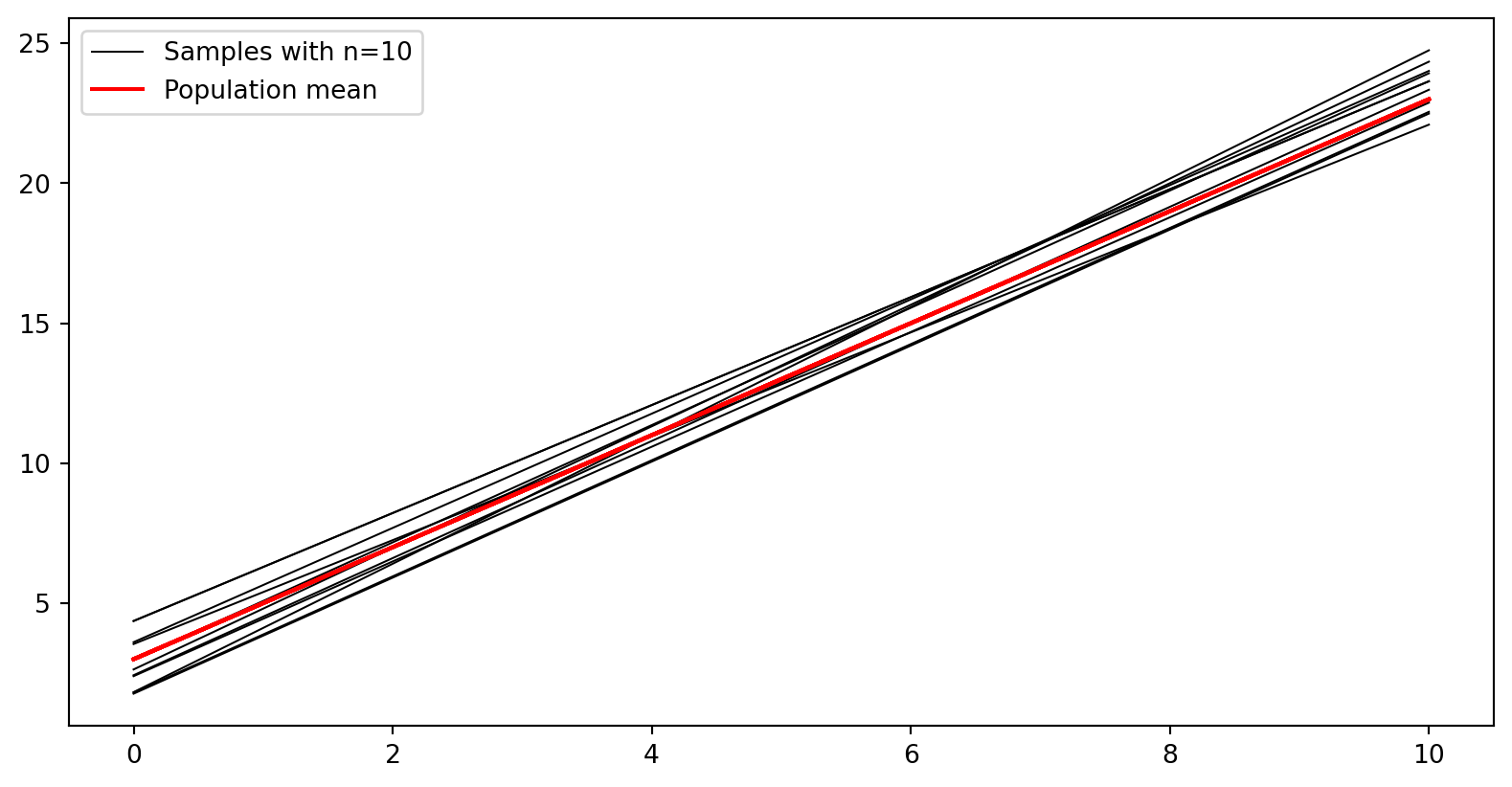
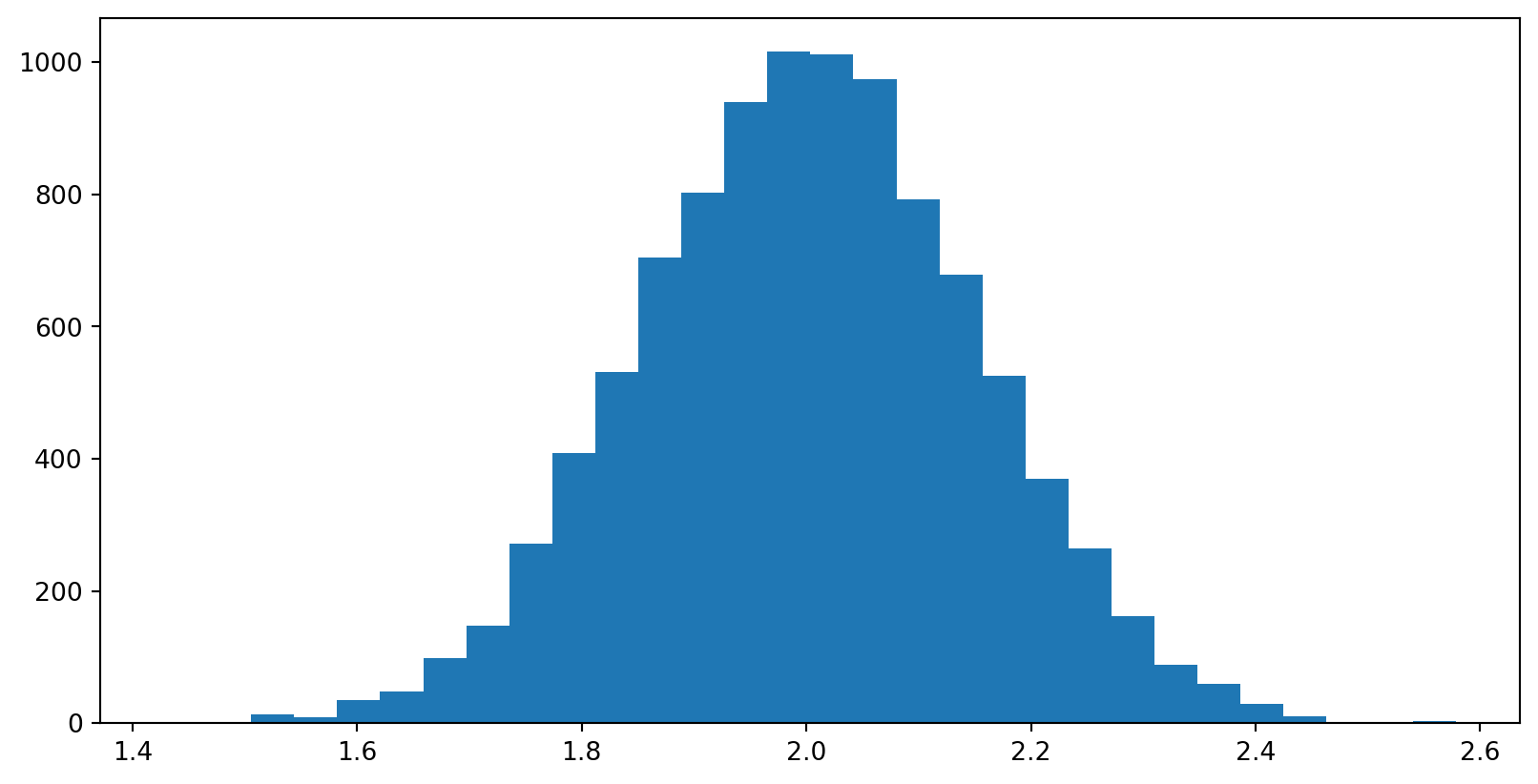
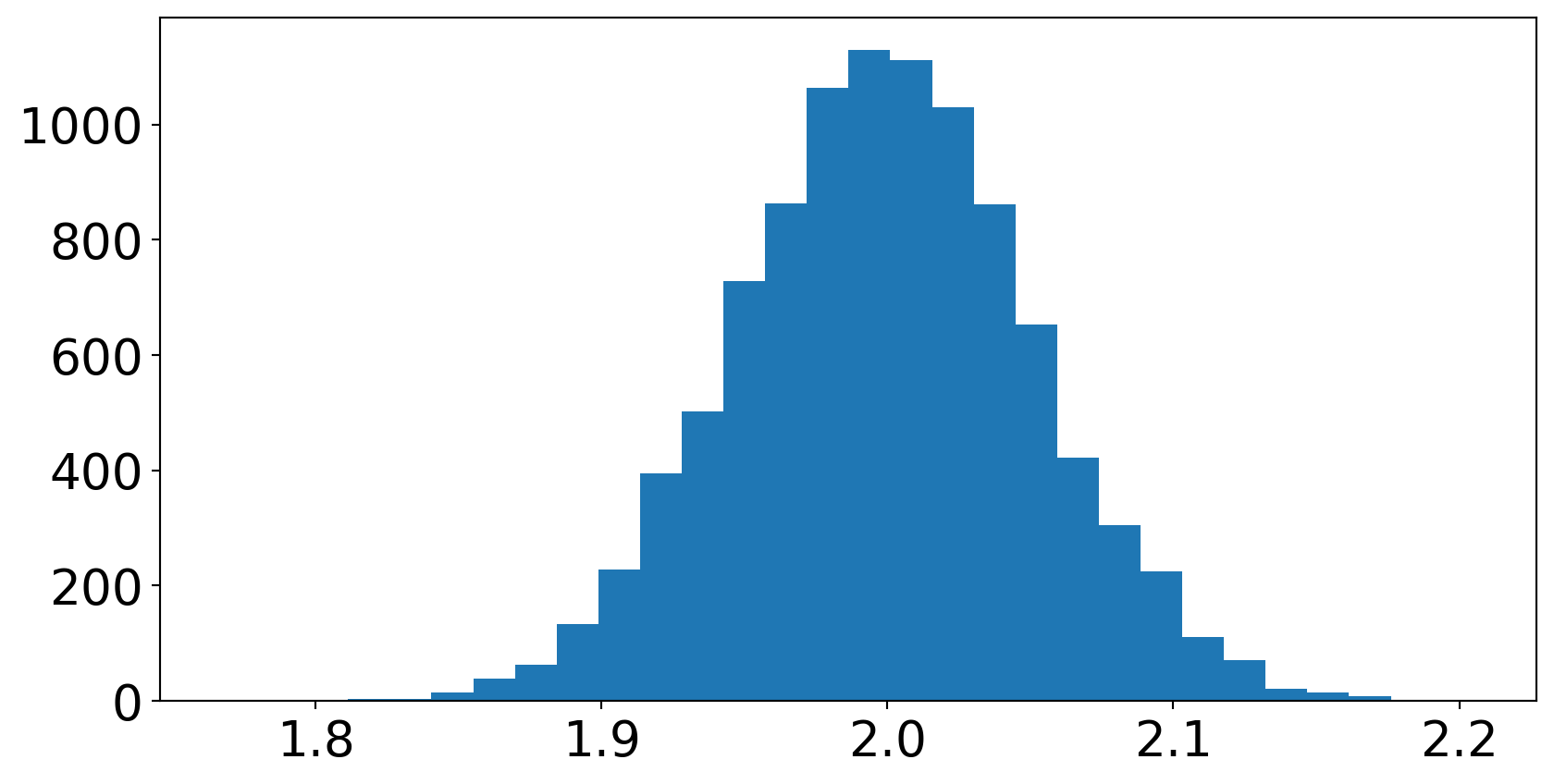
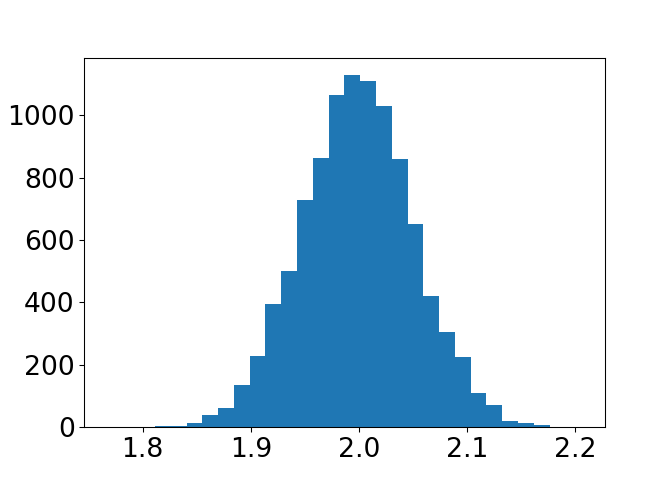
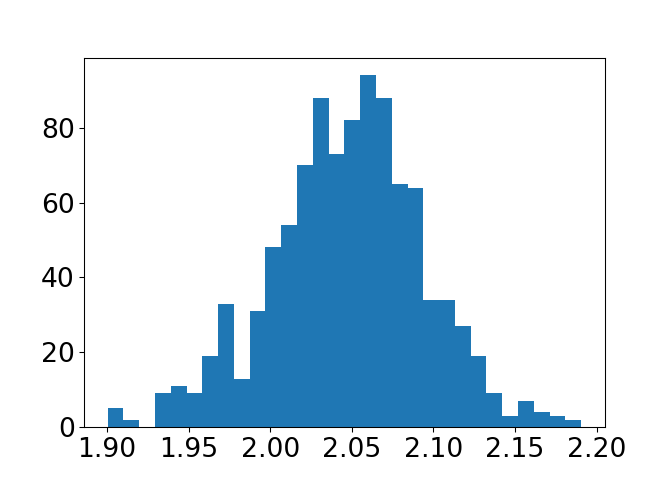
c) Gjenta mange ganger (f. eks 10000 i en for-løkke), og lagre stigningstallet som estimeres for hver enkelt linje. Plott et histogram over stigningstallene, med plt.hist.