Ta utgangspunkt i det klassiske datasettet som inneholder informasjon om størrelsen (lende og bredde) av begerbladene (engelsk: sepal) (de ytre bladene i en blomst) og kronbladene (engelsk: petal) til tre ulike typer Iris (setosa, versicolor og virginica) - på norsk hhv.: villiris, praktiris og blått flagg iris). Dere skal bruke dette datasettet til å se nærmere på lineær regresjon.
Oppgave 1
a) Les inn iris-datasettet med scikit-learn:
from sklearn import datasets import pandas as pdiris_data = datasets.load_iris()print(iris_data.keys())print(iris_data["feature_names"])print(iris_data["target_names"])
b) Få dataene inn i et Pandas-dataframe med riktige kolonnenavn. Man kan lage et dataframe av en numpy-array med flere kolonner ved å spesifisere hva kolonnene skal hete. Kolonnenavnene finnes i datasettet fra sklearn. Prøv deg fram og få evt. hjelp av en venn. Under er et eksempel, men du må selv finne ut hva du skal sette inn for data og columns når du lager dataframe. Lag en ny kolonne som inneholder navnet til de ulike iris-typene (target 0: setosa, 1: versicolor, 2: virginica).
Eksempelkode som kanskje er litt til hjelp:
import pandas as pddf = pd.DataFrame(data, columns=columns)display(df)
Løsningsforslag:
import numpy as np# Create a DataFramedf = pd.DataFrame(data=iris_data.data, columns=iris_data.feature_names)# Add a column with the target namesdf['species'] = pd.Categorical.from_codes(iris_data.target, iris_data.target_names)display(df)
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
species
0
5.1
3.5
1.4
0.2
setosa
1
4.9
3.0
1.4
0.2
setosa
2
4.7
3.2
1.3
0.2
setosa
3
4.6
3.1
1.5
0.2
setosa
4
5.0
3.6
1.4
0.2
setosa
...
...
...
...
...
...
145
6.7
3.0
5.2
2.3
virginica
146
6.3
2.5
5.0
1.9
virginica
147
6.5
3.0
5.2
2.0
virginica
148
6.2
3.4
5.4
2.3
virginica
149
5.9
3.0
5.1
1.8
virginica
150 rows × 5 columns
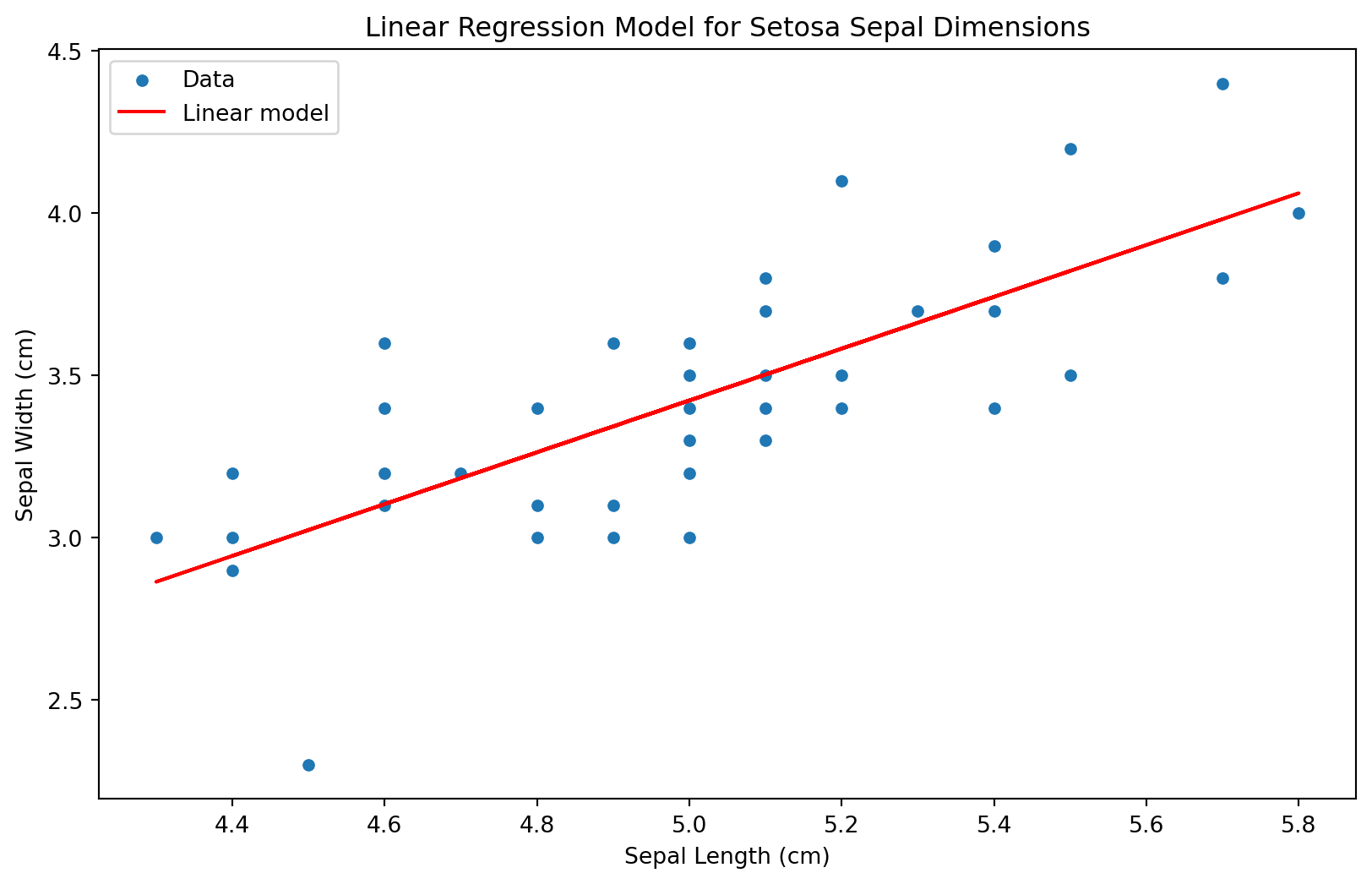
c) Lag en lineær modell som beskriver sammenhengen mellom lengden og bredden til begerbladene for en av de tre ulike typene Iris.
Plot modellen sammen med populasjonen?
Hva blir koeffisentene til modellen?
Løsningsforslag:
import matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.linear_model import LinearRegression# Filter the DataFrame for one species, e.g., setosasetosa_df = df[df['species'] =='setosa']# Define the modelmodel = LinearRegression()# Fit the modelX = setosa_df[['sepal length (cm)']]y = setosa_df[['sepal width (cm)']]model.fit(X, y)# Get the coefficientsintercept = model.intercept_[0]slope = model.coef_[0][0]print(f"Intercept: {intercept}, Slope: {slope}")# Plot the data and the modelplt.figure(figsize=(10, 6))sns.scatterplot(x='sepal length (cm)', y='sepal width (cm)', data=setosa_df, label='Data')plt.plot(setosa_df['sepal length (cm)'], model.predict(X), color='red', label='Linear model')plt.xlabel('Sepal Length (cm)')plt.ylabel('Sepal Width (cm)')plt.title('Linear Regression Model for Setosa Sepal Dimensions')plt.legend()plt.show()