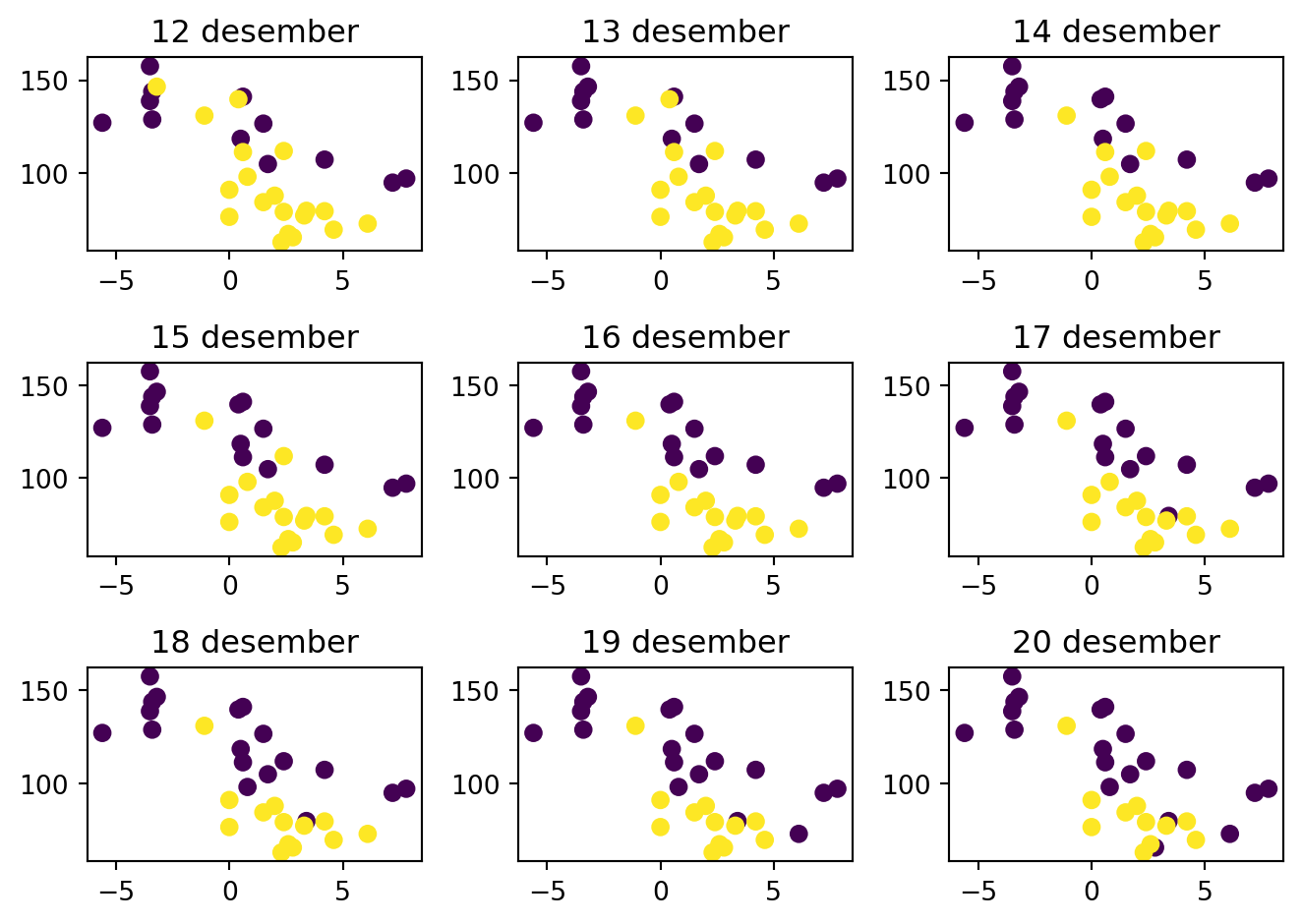
import numpy as npdag_varmepumpe_alternativer = np.arange(12, 21)for i, dag_varmepumpe inenumerate(dag_varmepumpe_alternativer): plt.subplot(3,3, i+1) forbruk_per_dag["is_varmepumpe"] = [0] * dag_varmepumpe+[1] * (31-dag_varmepumpe) x = df_temp["value"] y = forbruk_per_dag["KWH 60 Forbruk"] plt.scatter(x, y, c=forbruk_per_dag["is_varmepumpe"]) plt.title(f"{dag_varmepumpe} desember")plt.tight_layout()
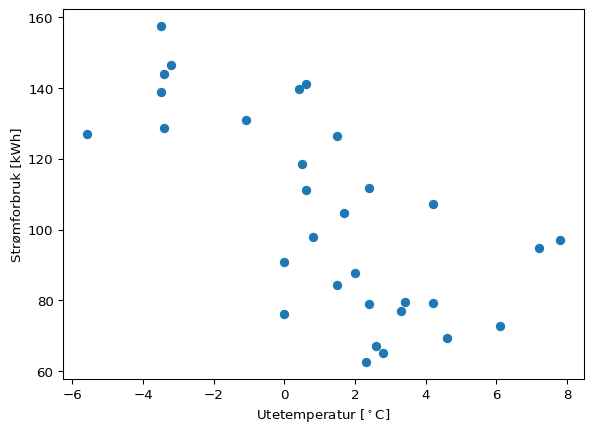
Så stirrer vi på grafene og ser etter om det er noe valg som gir oss to klare grupper med datapunkter.
Leseleksen
Skriv opp tre konsepter du forstod, og tre konsepter du ikke forstod
Oppgave
Skriv opp på tre forskjellige postit-lapper, konseptene du ikke forstod. Alle legger lappene sammen i en bunke. SÅ tar dere dem en og en og ser om dere kan få forklart dem på gruppa
Etterpå oppsummerer vi litt i plenum
Ohms lov og lineær regresjon
Fra strøm i naturfag på vgs/ungdomsskolen vet vi at \[U = RI \implies I = \frac{1}{R}U\]
Kan plotte:
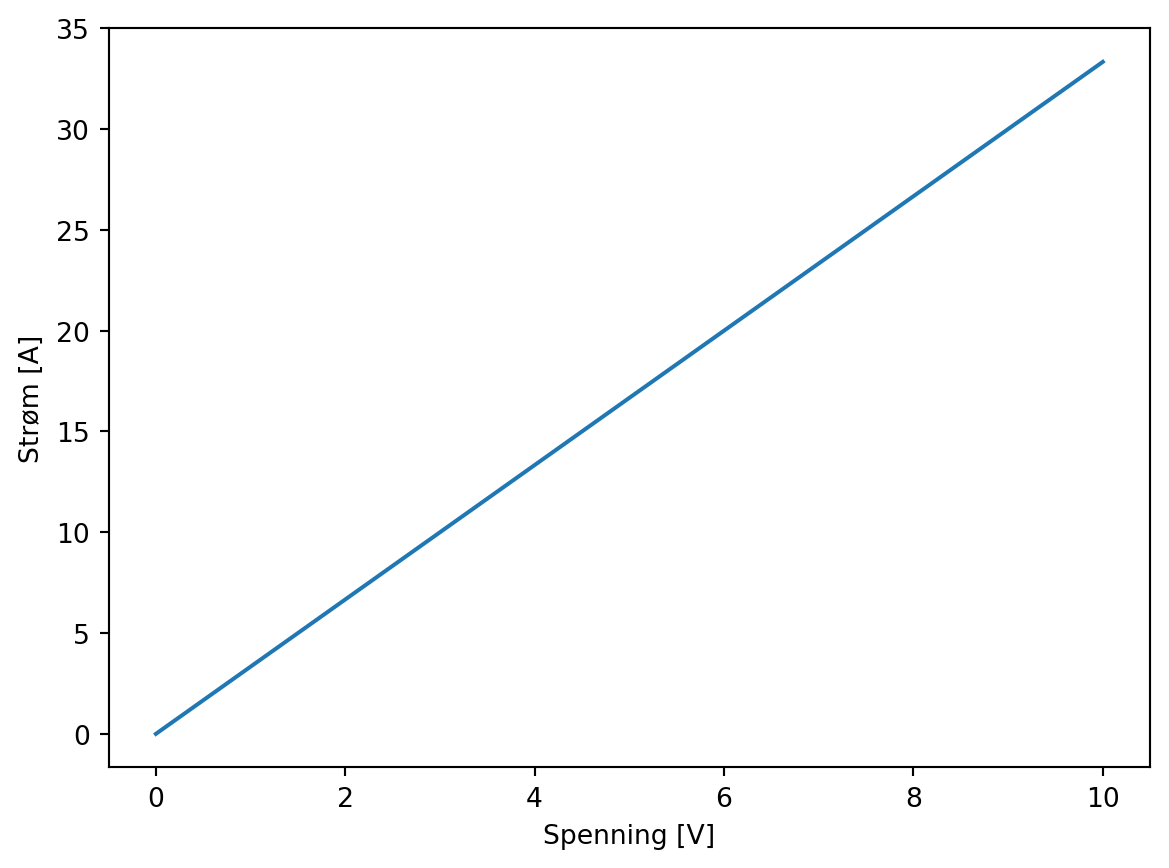
Strøm \(I\) er en lineær funksjon av spenning \(U\), med invers motstand som proporsjonalitetskonstant.
Måledata
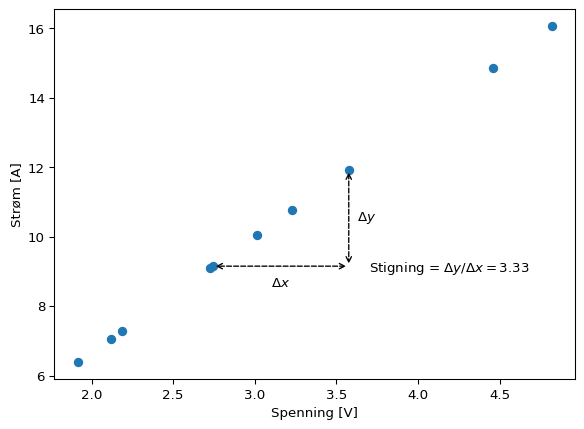
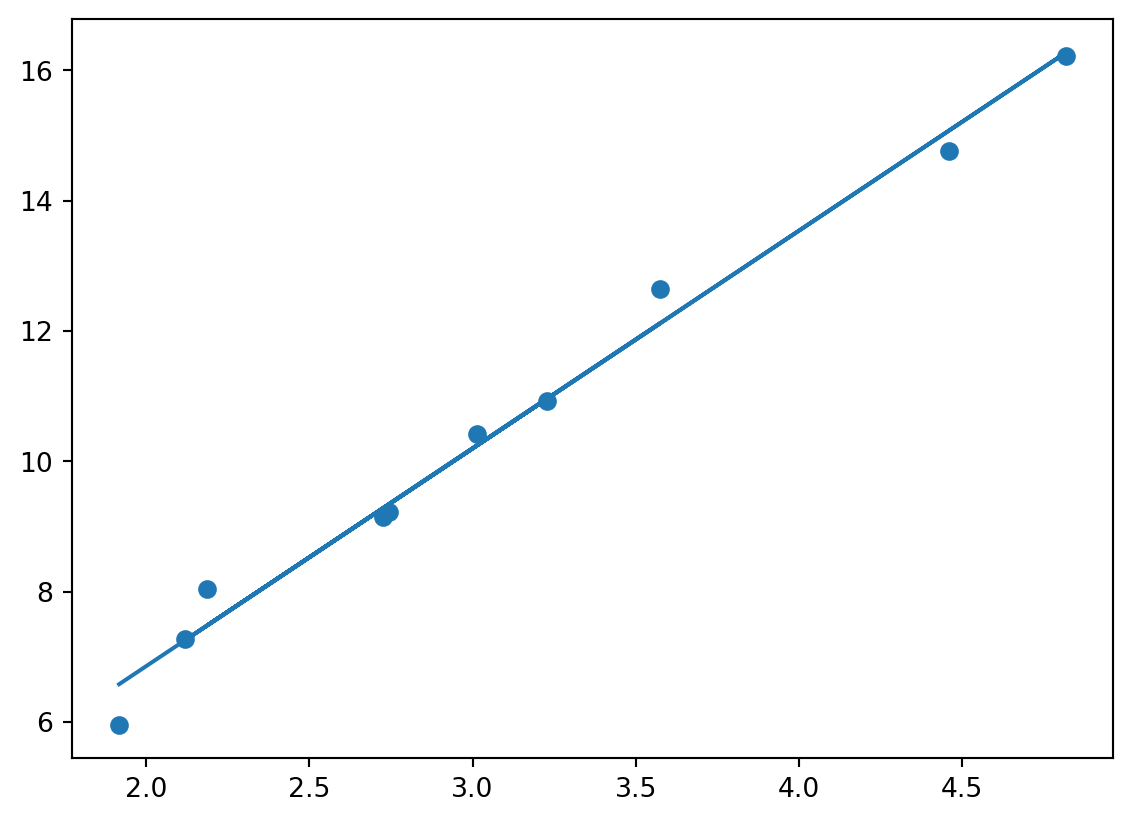
Vi går på laben og finner en Ohmsk motstand, og måler, da forventer vi å finne noe slikt:
Siden stigningen er 3.33…, så er motstanden \(0.3 \Omega\).
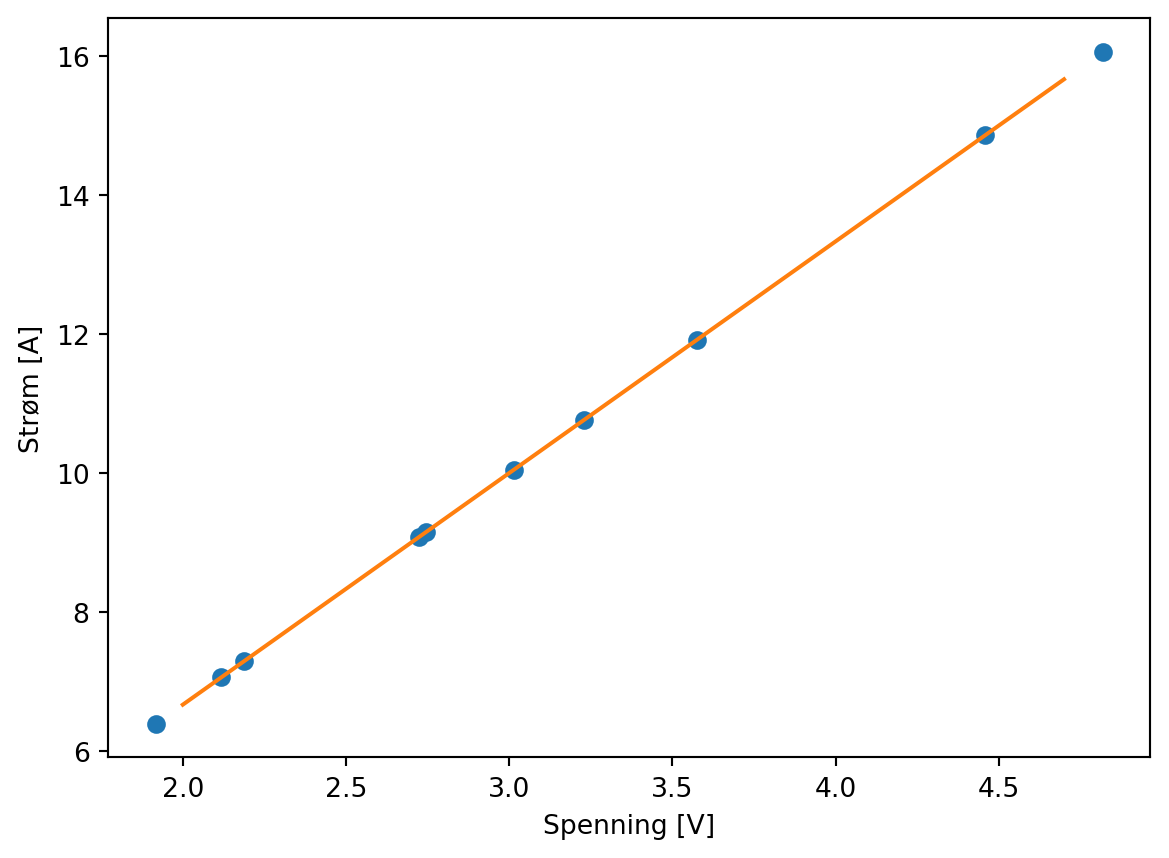
Dermed kan vi plotte en linje sammen med datapunktene
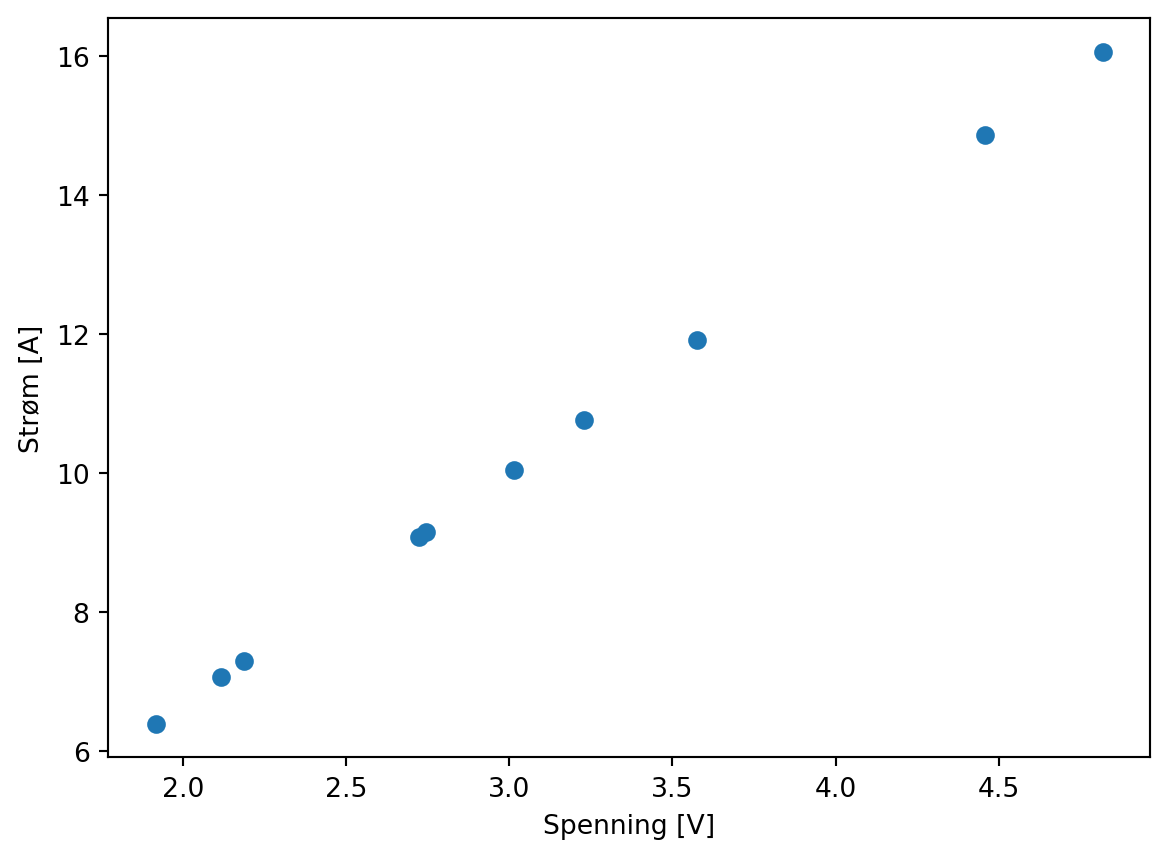
Men er det slik måleserier ser ut i virkeligheten?
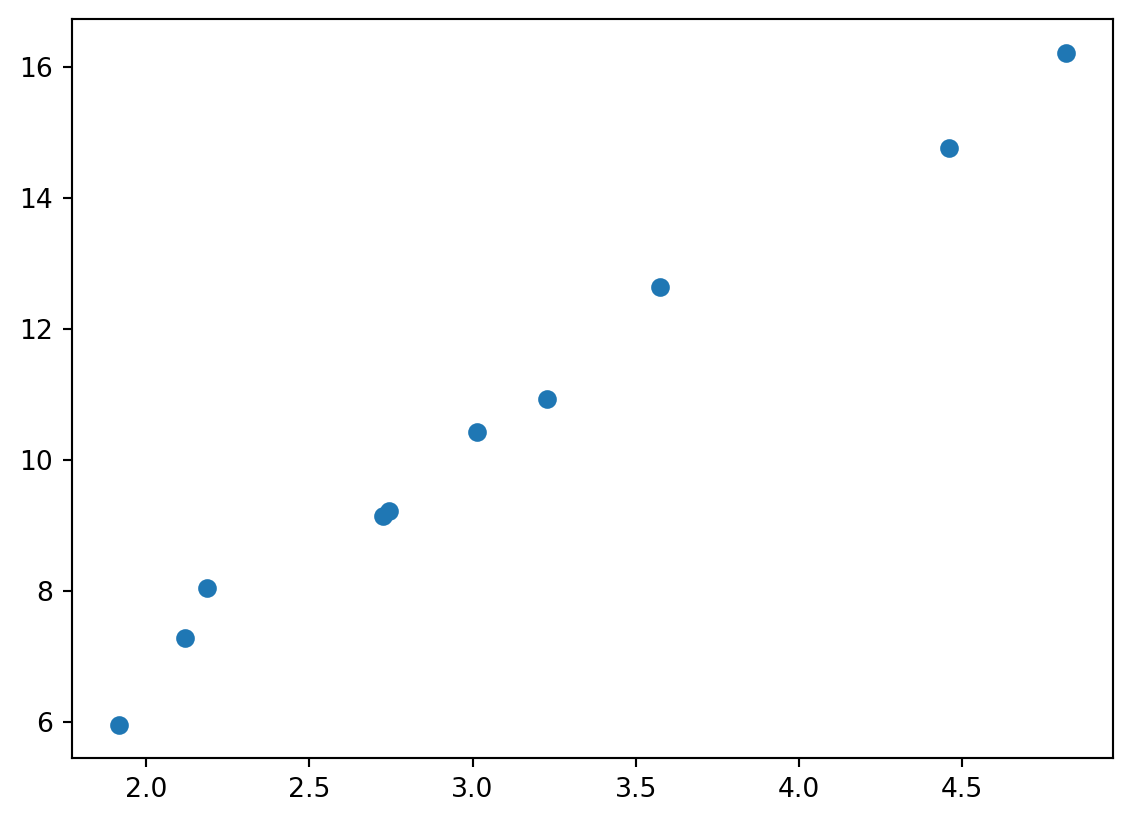
Støy
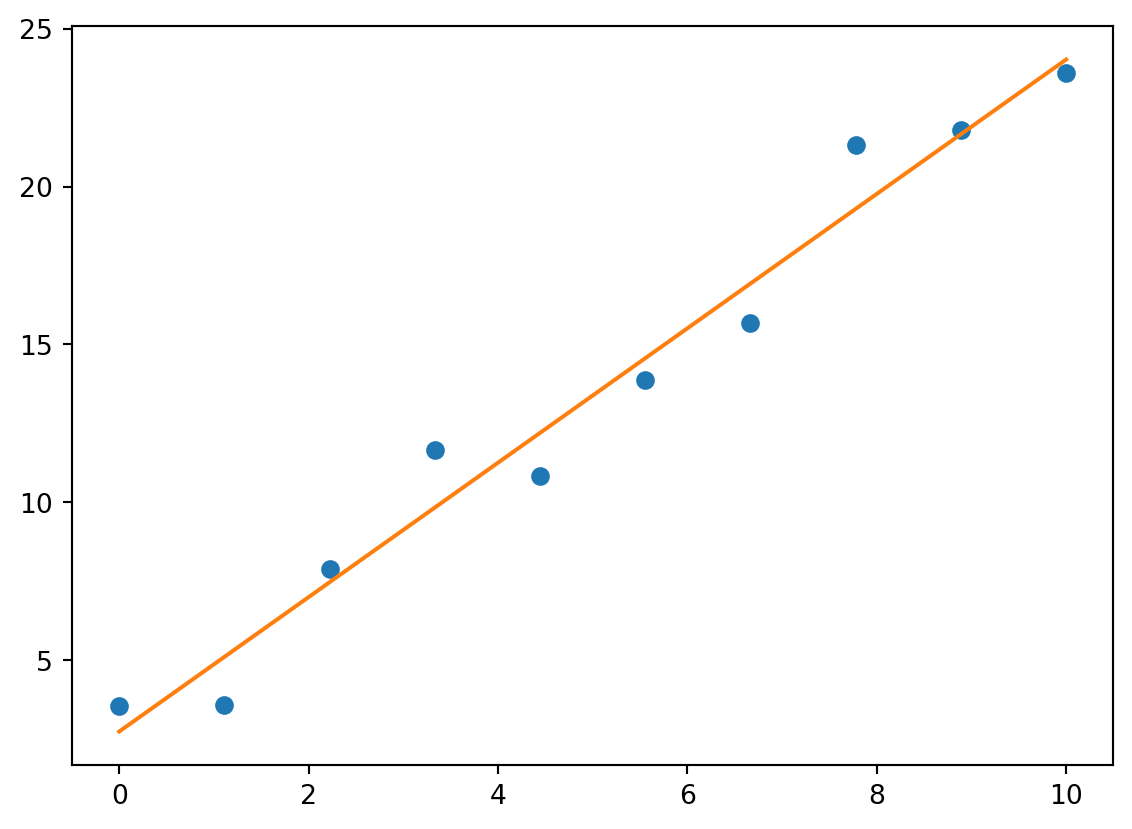
Vi får nok heller noe som ser slik ut:
import numpy as npimport matplotlib.pyplot as pltnp.random.seed(0)R =0.3U = np.random.random(10) *5I =1.0/ R * U + np.random.normal(0, 0.5, 10) # Current calculationplt.scatter(U, I)
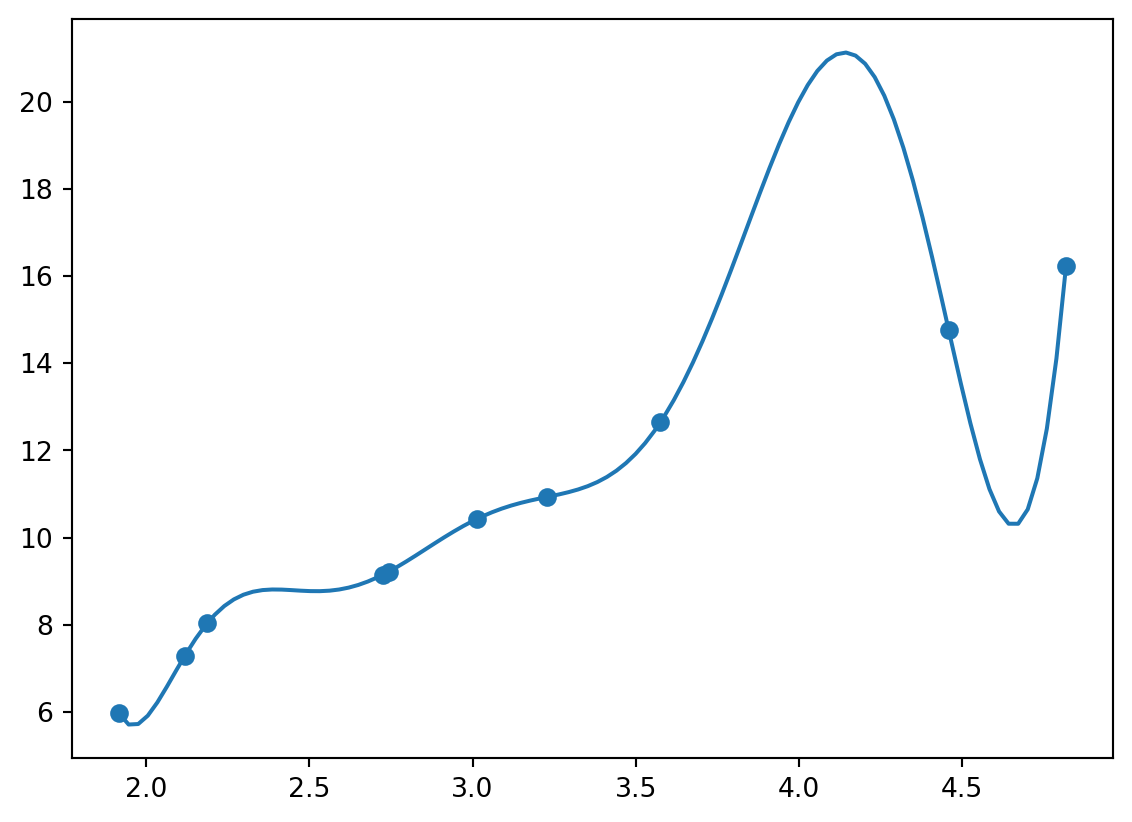
Er dette en god ide?
import numpy as npimport matplotlib.pyplot as pltnp.random.seed(0)R =0.3U = np.random.random(10) *5I =1.0/ R * U + np.random.normal(0, 0.5, 10) # Current calculationp = np.polyfit(U, I, 10)x = np.linspace(np.min(U), np.max(U), 100)plt.scatter(U, I)plt.plot(x, np.polyval(p, x))
/var/folders/qn/3_cqp_vx25v4w6yrx68654q80000gp/T/ipykernel_34680/659525506.py:8: RankWarning: Polyfit may be poorly conditioned
p = np.polyfit(U, I, 10)
Lineær regresjon
Nå må vi forholde oss til verden slik den er. Det er alltid en viss usikkerhet vi ikke klarer å forklare uansett hvor god modell vi har. \[y=f(x) + \varepsilon\]
Der \(\varepsilon\) representeter en usikkerhet som vi ikke klarer å plukke opp med vår modell av fenomenet.
Lineær regresjon
Vi ønsker å finne parametre \(\beta_0\) og \(\beta_1\) i funksjonen \[f(x) = \beta_1 x + \beta_0\]
Slik at når vi sier at \(\hat{y} = f(x)\), så minimerer vi
Skriv opp for deg selv, hva som er sammenhengen mellom den rette linja og datapunktene her om vi har gjort lineær regresjon.
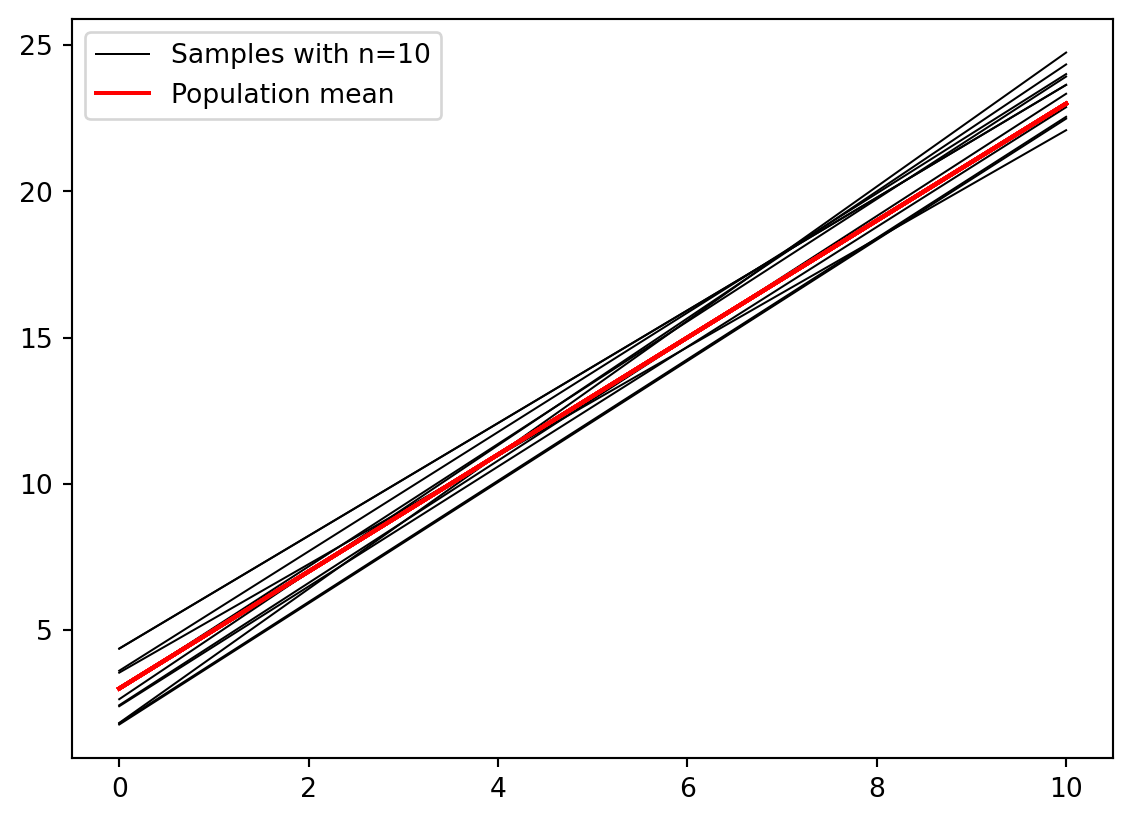
Prøve flere ganger
def f(x): return2*x +3N =10slopes = []for i inrange(N): x = np.linspace(0, 10, 10) y = f(x) + np.random.normal(0, 1.5, 10) p = np.polyfit(x, y, 1) slopes.append(p[0]) y_fit = np.polyval(p, x) plt.plot(x, y_fit, linewidth=0.75, color="k") plt.plot(x, f(x), color="r")plt.plot(x, y_fit, linewidth=0.75, color="k", label="Samples with n=10")plt.plot(x, f(x), color="r", label="Population mean")plt.legend()
Trekke mange ganger
Oppgave
a) Lag deg en affin funsjon (f. eks \(f(x) = 2x + 3\)). Trekk 10 tilfeldige tall, beregn \(f(x) + \varepsilon\) der du setter inn et tilfeldig normalfordelt tall som \(\varepsilon\) med np.random.normal(...). Verifiser med et plott at ting fungerer som de skal
b) Gjør en lineærtilpasning med np.polyfit(x, y, 1). Plott lineærtilpasningen sammen med de litt spredte punktene dine.
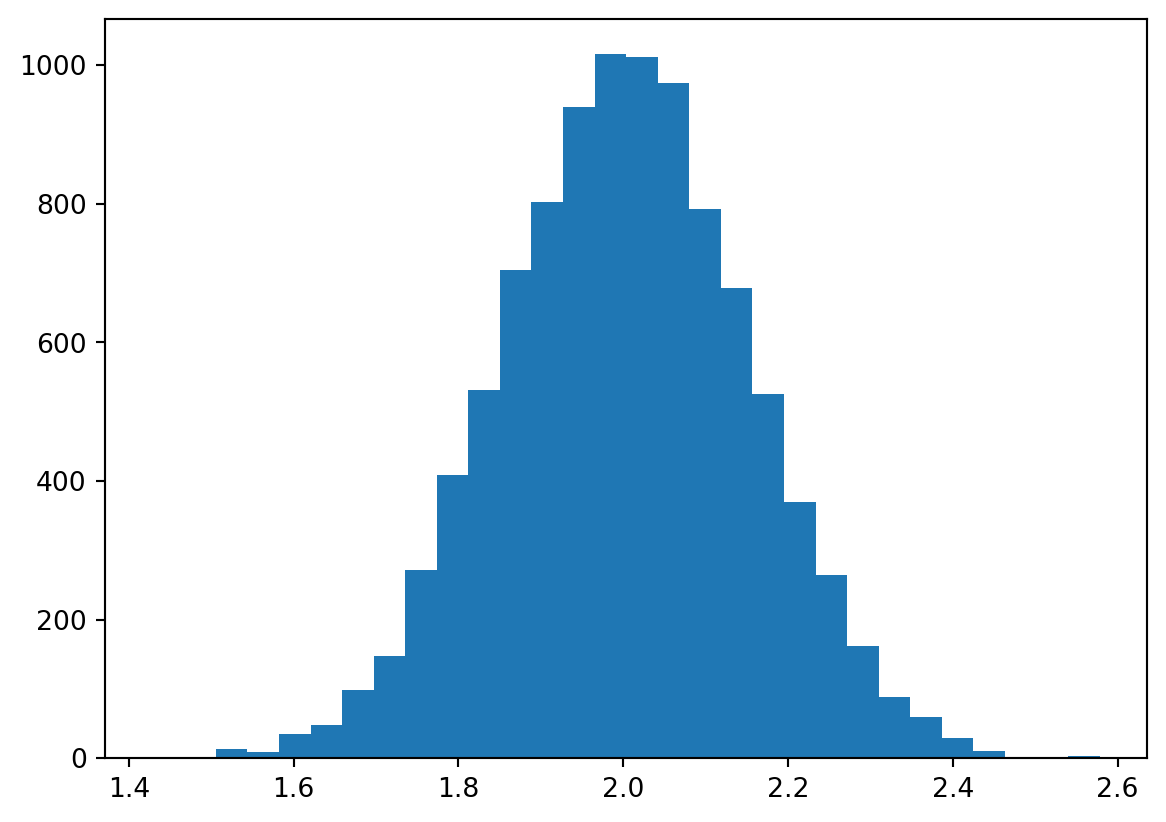
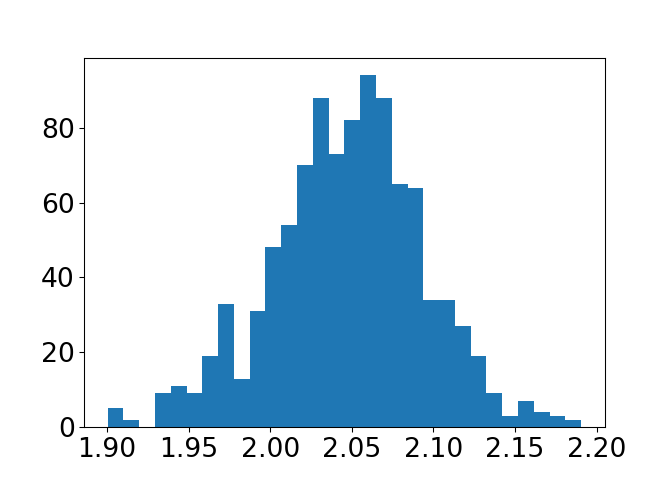
c) Gjenta mange ganger (f. eks 10000 i en for-løkke), og lagre stigningstallet som estimeres for hver enkelt linje. Plott et histogram over stigningstallene, med plt.hist.
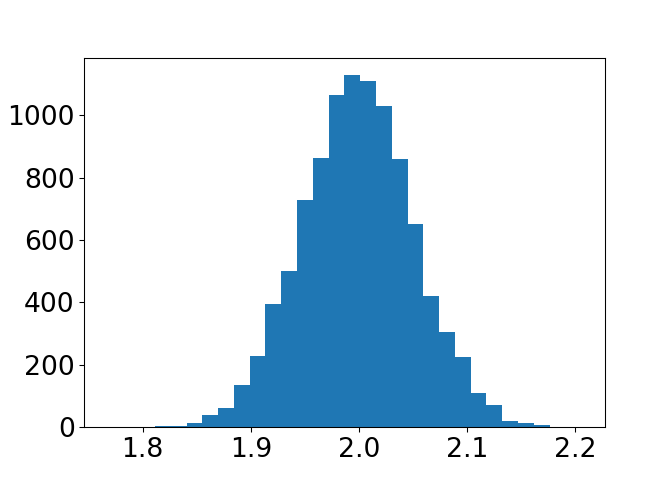
N =10000slopes = []for i inrange(N): x = np.linspace(0, 10, 10) y = f(x) + np.random.normal(0, 1.5, 10) p = np.polyfit(x, y, 1) slopes.append(p[0])_ = plt.hist(slopes, bins=30)
Øke antallet punkter til 100
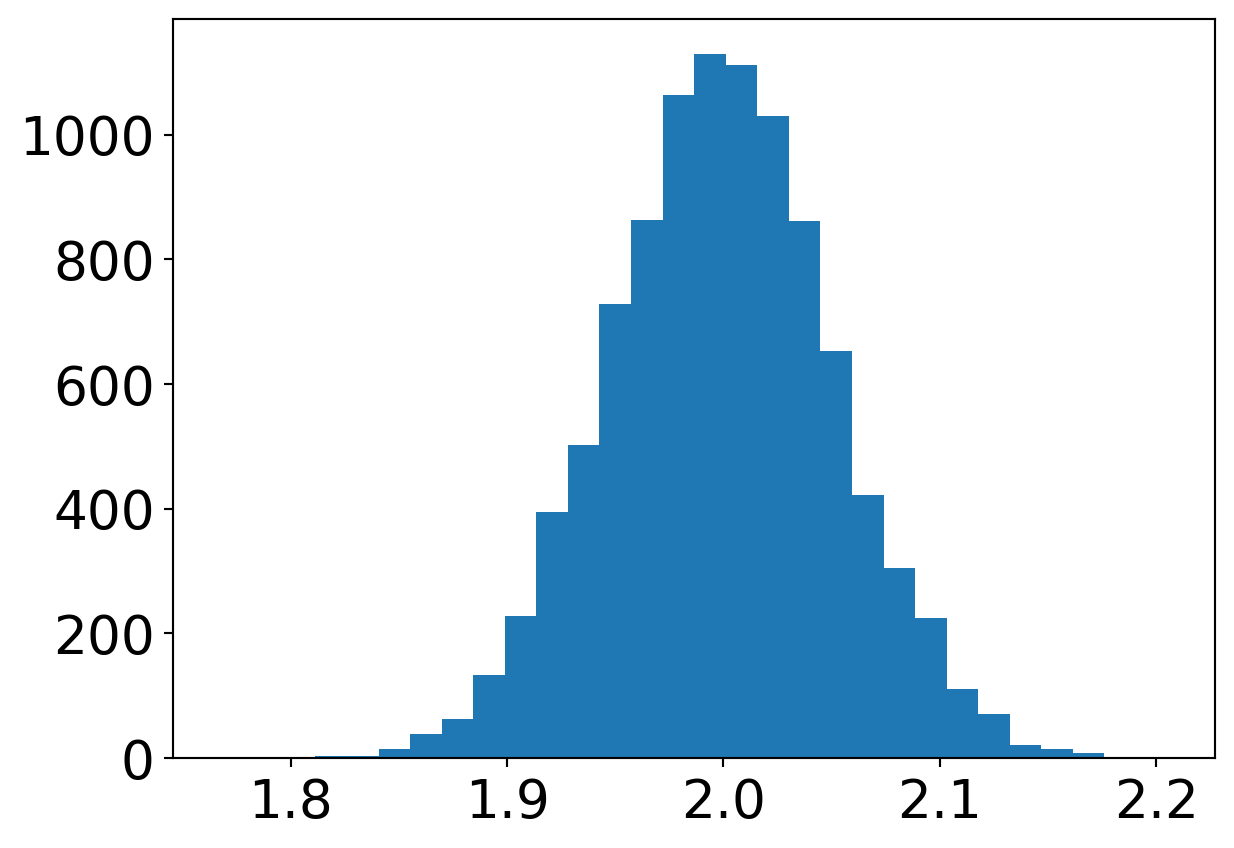
N =10000slopes = []for i inrange(N): x = np.linspace(0, 10, 100) y = f(x) + np.random.normal(0, 1.5, 100) p = np.polyfit(x, y, 1) slopes.append(p[0])_ = plt.hist(slopes, 30)plt.xticks(fontsize=20)plt.yticks(fontsize=20)plt.savefig("figures/est_beta1.png")
Hva skjedde med fordelingen av stigningstall?
Tolkning
Kort diskusjonsoppgave
a) Hva skjedde med fordelingen av stigningstall ved lineær regresjon da vi økte fra 10 til 100 punkter?
b) Hvordan skal vi tolke dette?
Feilestimat
Fra boka har vi følgende formel for forventet feil i stigningtallet: \[\mathrm{SE}(\hat{\beta}_1) = \sqrt{\frac{\sigma^2}{\sum_{i=1}^n(x_i-\bar{x})^2}}\]
der \(\sigma\) er standardavviket til den tilfeldige variablen \(\varepsilon\) i \(y = f(x) + \varepsilon\)
Anvendt på våre tall
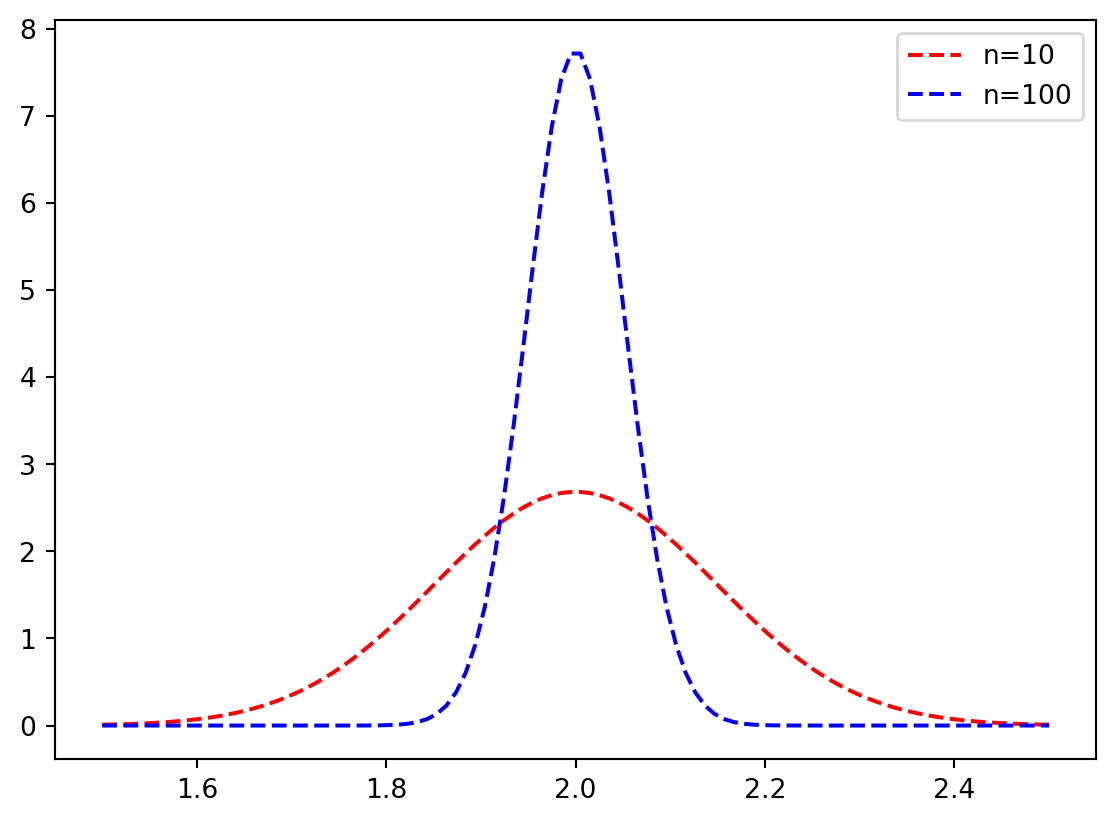
Vi trakk tilfeldige tall med \(\sigma=1.5\) og hhv. 10 og 100 jevnt fordelte tall fra 0 til 10. Altså:
x = np.linspace(0, 10, 10)se = np.sqrt(1.5**2/np.sum((x-np.mean(x))**2))print(f"Standard feil for n=10: {se}")x = np.linspace(0, 10, 100)se = np.sqrt(1.5**2/np.sum((x-np.mean(x))**2))print(f"Standard feil for n=100: {se}")
Standard feil for n=10: 0.1486301082920587
Standard feil for n=100: 0.051444481273168134
Normalfordelinger med disse parametrene:
def est_dist(x, mu, std):return1/np.sqrt(2*np.pi*std**2)*np.exp(-(x-mu)**2/(2*std**2))for n, color inzip([10, 100], ["red", "blue"]): x = np.linspace(0, 10, n) se = np.sqrt(1.5**2/np.sum((x-np.mean(x))**2)) est_vals = np.linspace(1.5, 2.5, 100) plt.plot(est_vals, est_dist(2, est_vals, se), "--", color=color, label=f"n={n}")plt.legend()
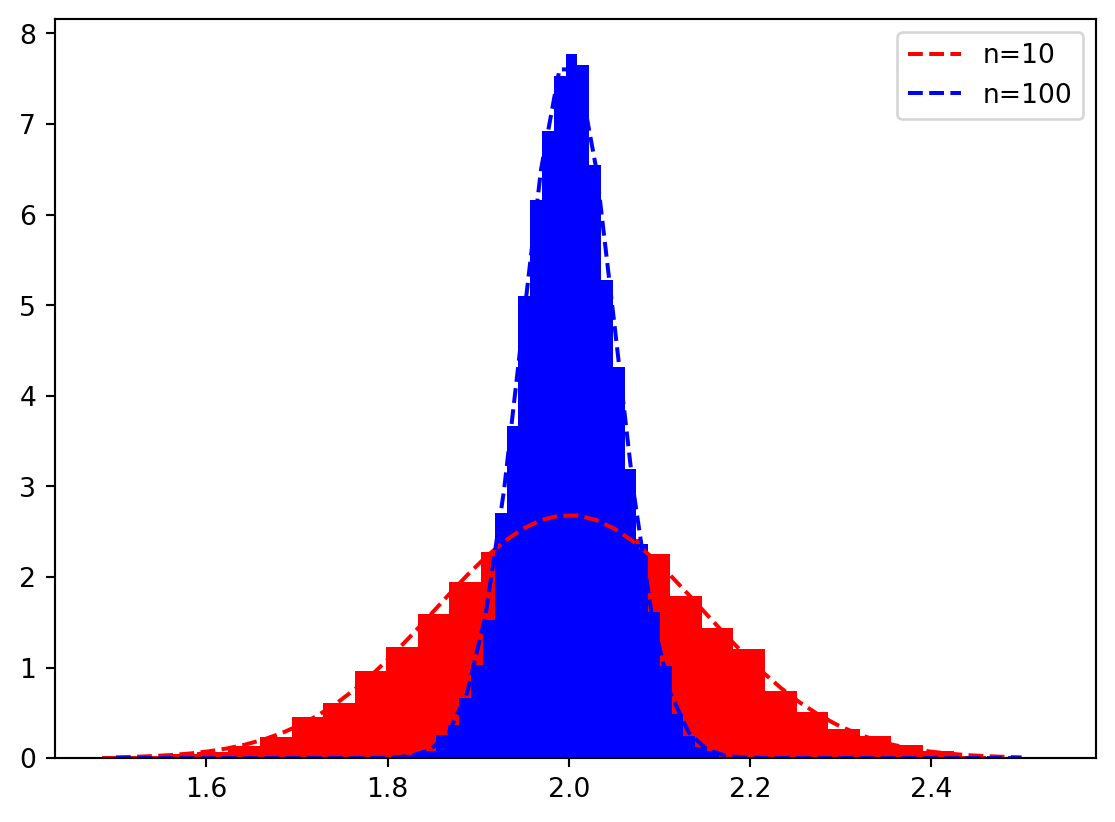
Normalfordelinger sammen med datasettene
def est_dist(x, mu, std):return1/np.sqrt(2*np.pi*std**2)*np.exp(-(x-mu)**2/(2*std**2))N =10000for n, color inzip([10, 100], ["red", "blue"]): slopes = []for i inrange(N): x = np.linspace(0, 10, n) y = f(x) + np.random.normal(0, 1.5, n) p = np.polyfit(x, y, 1) slopes.append(p[0]) _ = plt.hist(slopes, 30, color=color, density=True) se = np.sqrt(1.5**2/np.sum((x-np.mean(x))**2)) est_vals = np.linspace(1.5, 2.5, 50) plt.plot(est_vals, est_dist(2, est_vals, se), "--", color=color, label=f"n={n}")plt.legend()
Men om vi har målt noe, så har vi jo bare én måleserie. Hva kan vi gjøre da?